Flowith 产品体验报告(2025.9)
flowith 产品体验报告
核心理念
我们认为,像人与人的互动和协作一样,人和 AI 最佳的互动方式应该是发散、多线程、和相互协作的,因此,我们首创性地设计了和传统对话式 GPT 助手完全不同的 AI 互动方式,通过一个无限的画布,让你和 AI 可以更自由的协作,既可以无限发散,也可以通过清楚的流程把它转化成可复用的工作流。
特点
与传统聊天界面的线性对话方式相比,flowith 采用二维画布交互格式。用户可以参与多线程对话,更能适应各种复杂的任务和创造性的过程。
无限工具调用
Oracle 模式支持集成外部工具(可以理解为插件),例如 Twitter 搜索、小红书搜索、摘要推理、思维导图生成、PPT 制作、网页生成等。它会根据当前子任务,自主从工具库中选择最合适的工具,并按需调用。Oracle 支持的工具数量持续增加,其框架允许无限数量的工具集成。
人工智能驱动的自动化知识组织
Flowith 会自动对您上传的文档、笔记、链接等资料进行拆分,无需人工分类和标记,大幅降低知识整理的时间成本。此外,系统会自动建立知识单元之间的连接,构建结构化的知识网络,消除信息孤岛,使知识检索和利用更加高效便捷。
更精准、更专业的回应
Flowith 自动将材料分解为 AI 可理解的基本知识单元,称为“种子”。每个种子包含核心概念或关键点。通过 AI 的深度理解和检索能力,可以精准地访问这些种子,从而提供更精准、更符合语境的支持。系统能够深入理解您知识库的语境,告别“幻觉”和无效的响应。
优势
Flow 模式具体的优势:
-
可以多 AI 同时、多线程进行生成。
-
你可以反复修改 AI Prompt,并多次生成。
-
每个节点可以 「 引用 」 其他节点中的内容,让内容可复用
-
可以对信息随时进行分叉,或汇总
-
随时删减不必要的信息
-
可以轻松地对比不同模型的生成效果,让它们同时并行生成内容
说明文档:doc.flowith.io
产品架构
知识花园(知识库)
解决的问题:
-
信息离散无序:笔记、文档分散在各个软件、文件夹、浏览器标签,知识无法形成体系化的沉淀,难以快速找到需要的信息;每次启动工作时,你面对的都是一个个空白页面,然后需要在无数文件、软件与页面间四处搜索和拷贝信息,重头开始或撰写或编撰成冗长的 prompt 喂给 AI。
-
协作隔离低效:你和你的团队成员的知识无法共享,每次都要寻找一个数个月甚至数年前的文档上的某段信息,导致沟通成本高昂、产出质量参差不齐。
-
AI 生成内容没有针对性:大语言模型过于通用,AI 缺乏个人知识和专业领域的理解,导致难以根据个人背景产生符合要求的内容并且容易产生"幻觉"给出错误信息,无法确保回答的一致性。
知识管理模块:
-
快速创建个人知识库:无需从头开始,只要导入已有的资料和文件,flowith AI 就会借助 Seed 系统将其自动分解为知识的最小单元进行自动化知识管理、快速搭建你的 AI 知识库。
-
**自动化匹配和生成:**在你使用 AI 进行特定任务时,flowith 会自动匹配你选择的知识库下有价值的信息,这让 flowith 知识库成为一个真正智能、有生命力的第二大脑系统,帮助你更自然地管理和运用知识。
-
**联通知识管理和内容生成:**你的内容会被自动建立关联,形成一个有机且智能的知识网络,确保回答的准确性并有效避免“幻觉”现象,显著提升生成质量。
-
**显著降低使用门槛:**专注在个人知识库的搭建,而非复杂的提示词工程上,即可与 AI 进行自然的对话,使用和共享社区知识库,帮助你大幅节省工作成本或是让你的知识盈利。
示例:
| 步骤 | 截图 | 说明 |
|---|---|---|
| 第一次使用 | 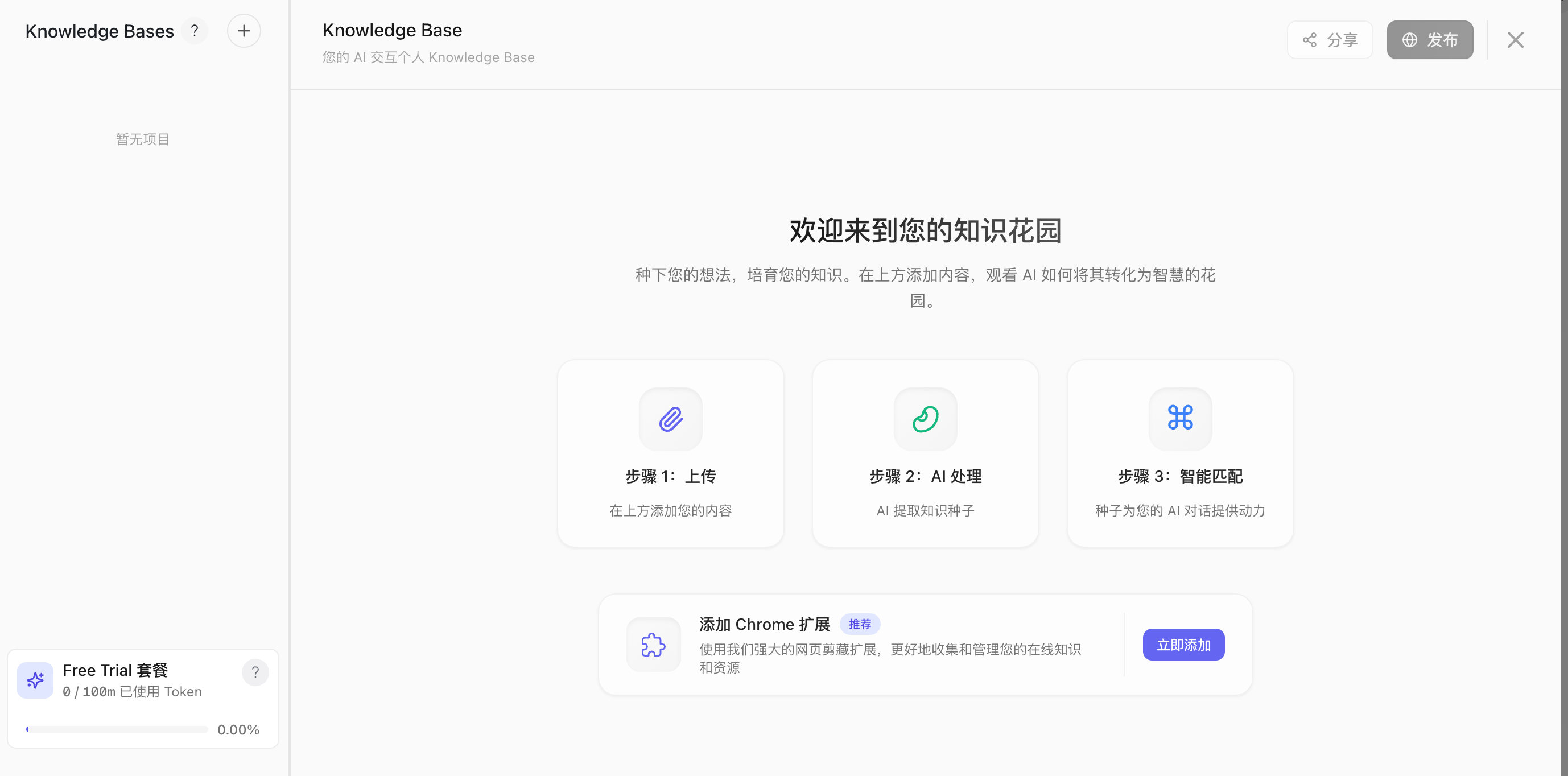 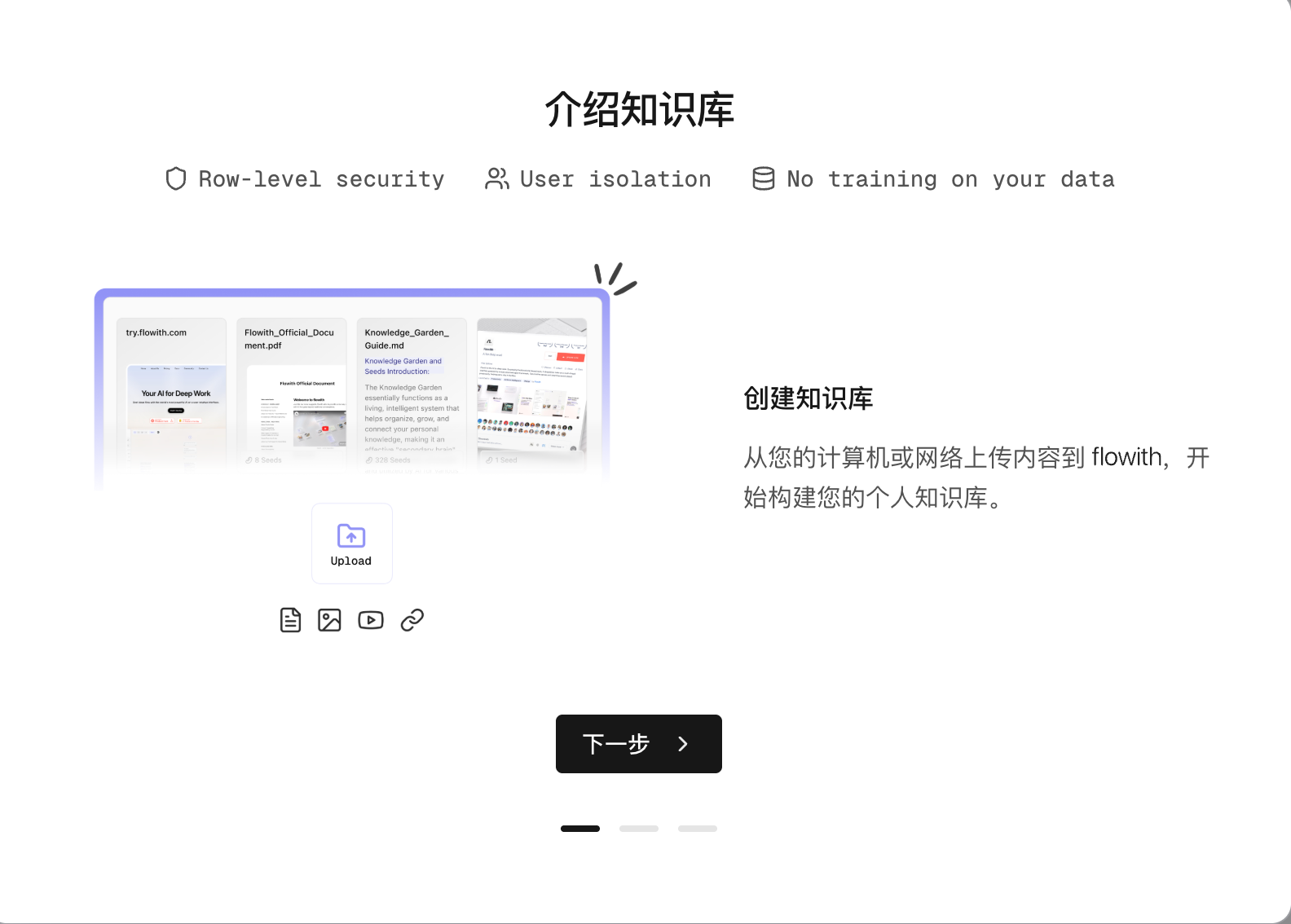 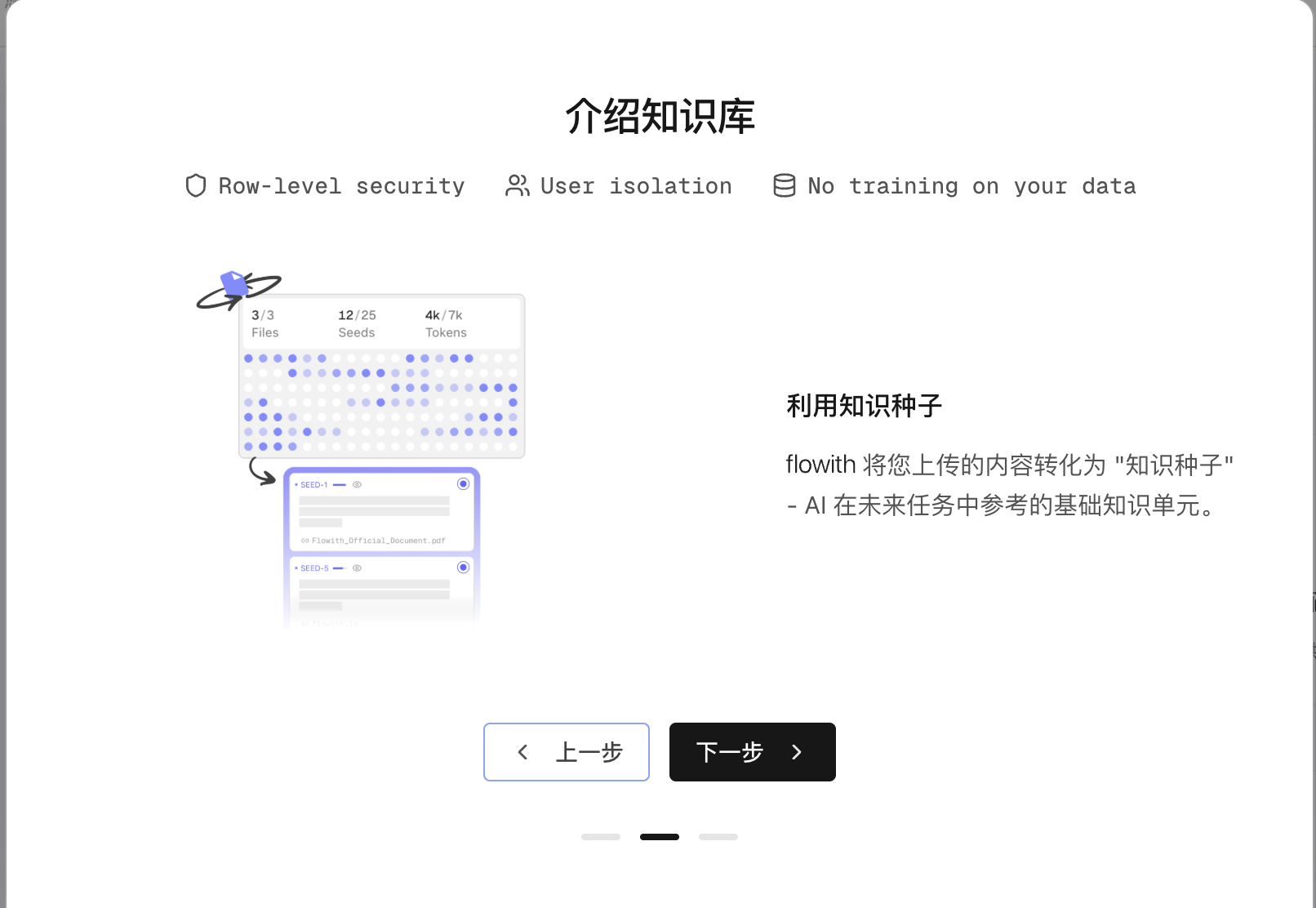 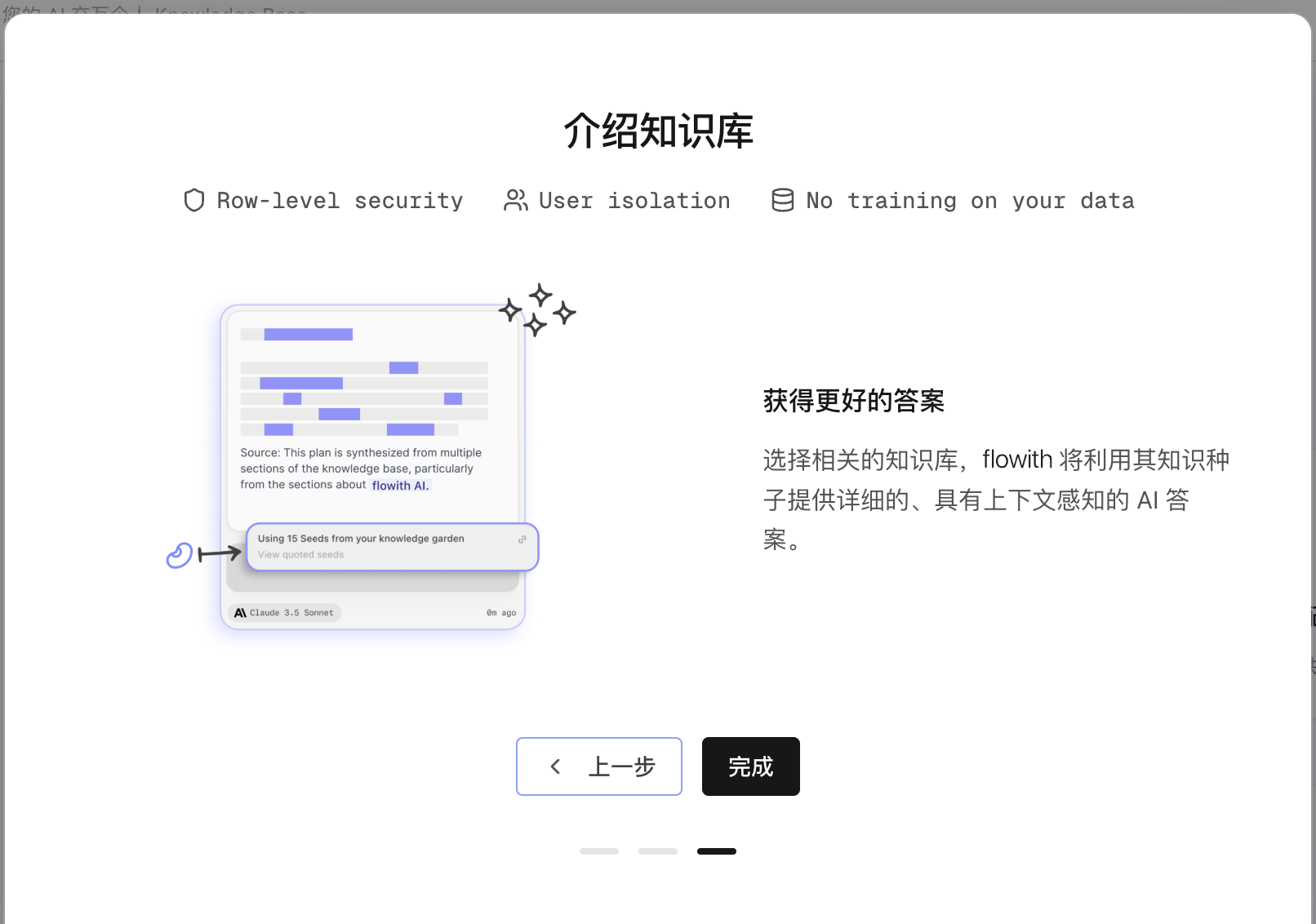 | 第一次使用会有功能引导,其实就是 RAG。 上传文档➡️解析切片➡️问答时检索引用 - 长度要求: - 内容长度灵活,可处理包含相关关键词的任意文本 - 不支持文本摘要生成功能 - 超过1,000字符的源文本将自动分段处理 - 文件格式规范: - 无特定格式限制,但不支持PDF图像识别 - 图片需单独上传,嵌入长文本中的图片将被忽略 - 不支持代码的读取和处理 - 支持的内容类型: - 支持单独的图片上传 - 完全支持基于文本的内容 - 长篇内容需要分段处理 |
| 新建知识库 | 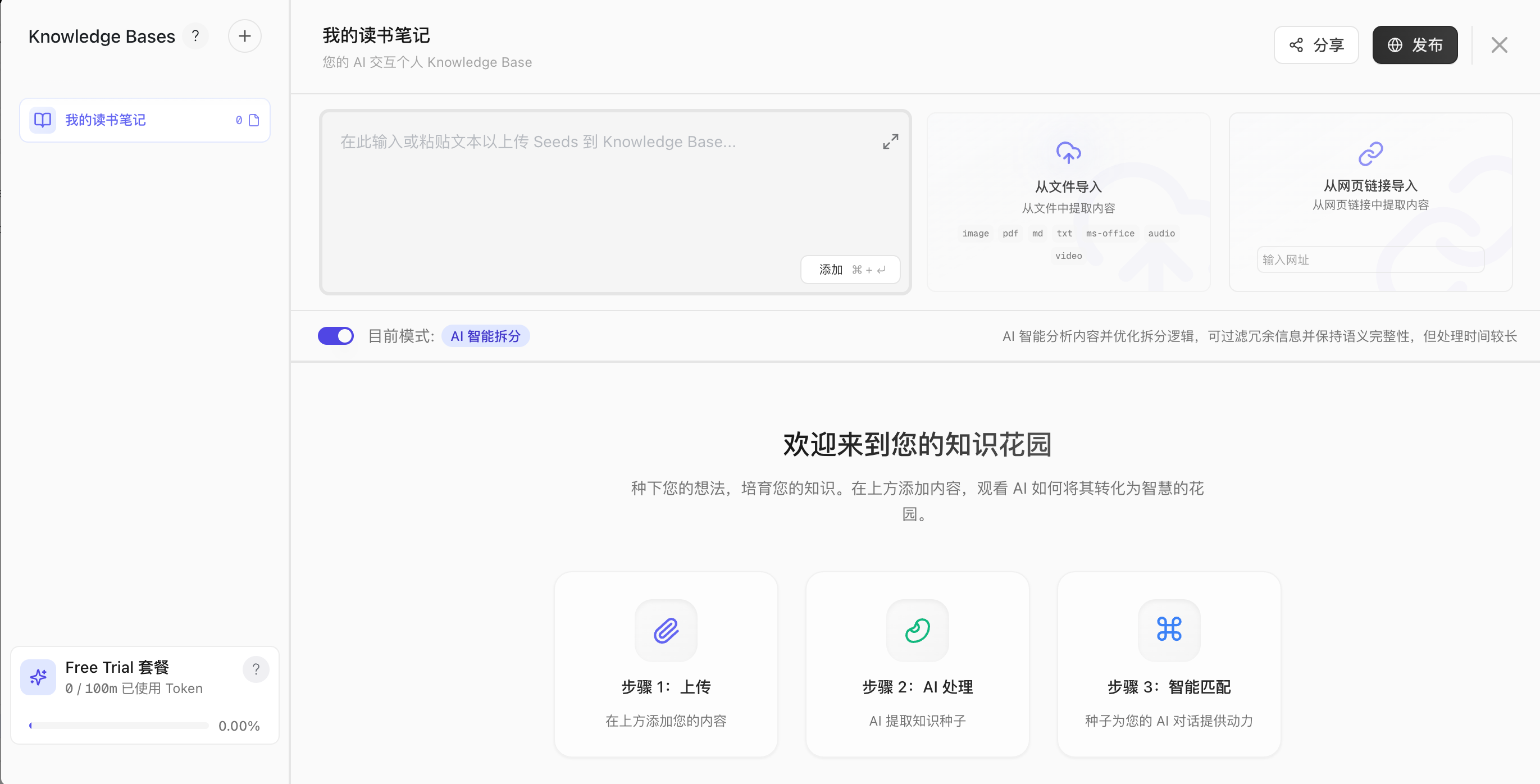 | 解析模式有两种: - AI 智能拆分:AI 智能分析内容并优化拆分逻辑,可过滤冗余信息并保持语义完整性,但处理时间较长 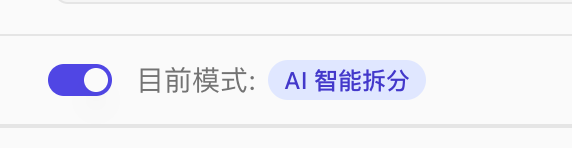 - 快速拆分:按句子直接拆分,完整保留原文,处理速度快但不作优化 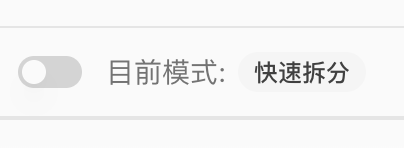 |
| 上传文档 | 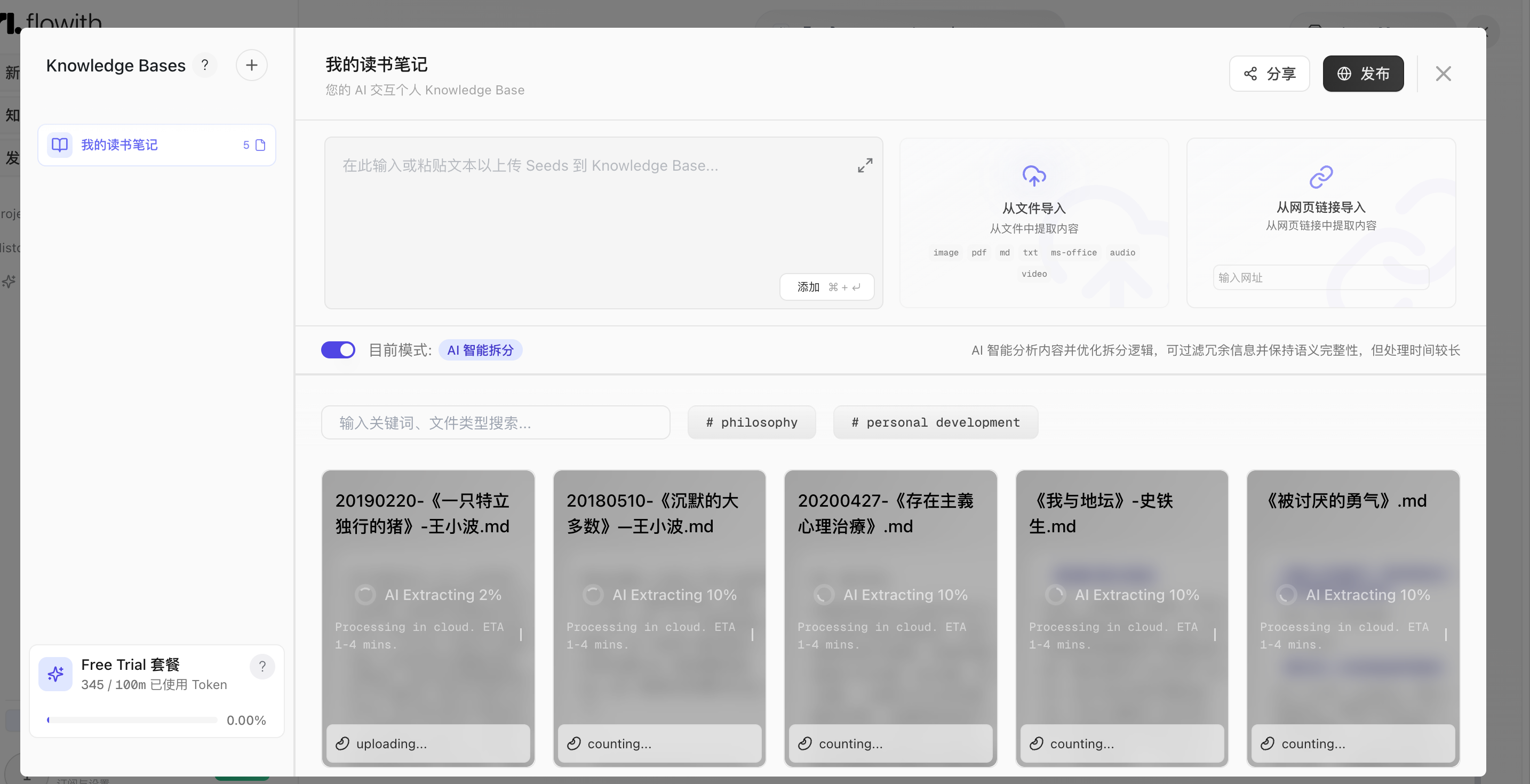 | AI 自动拆分,每个文件需要 1-4 分钟 |
| 上传后 | 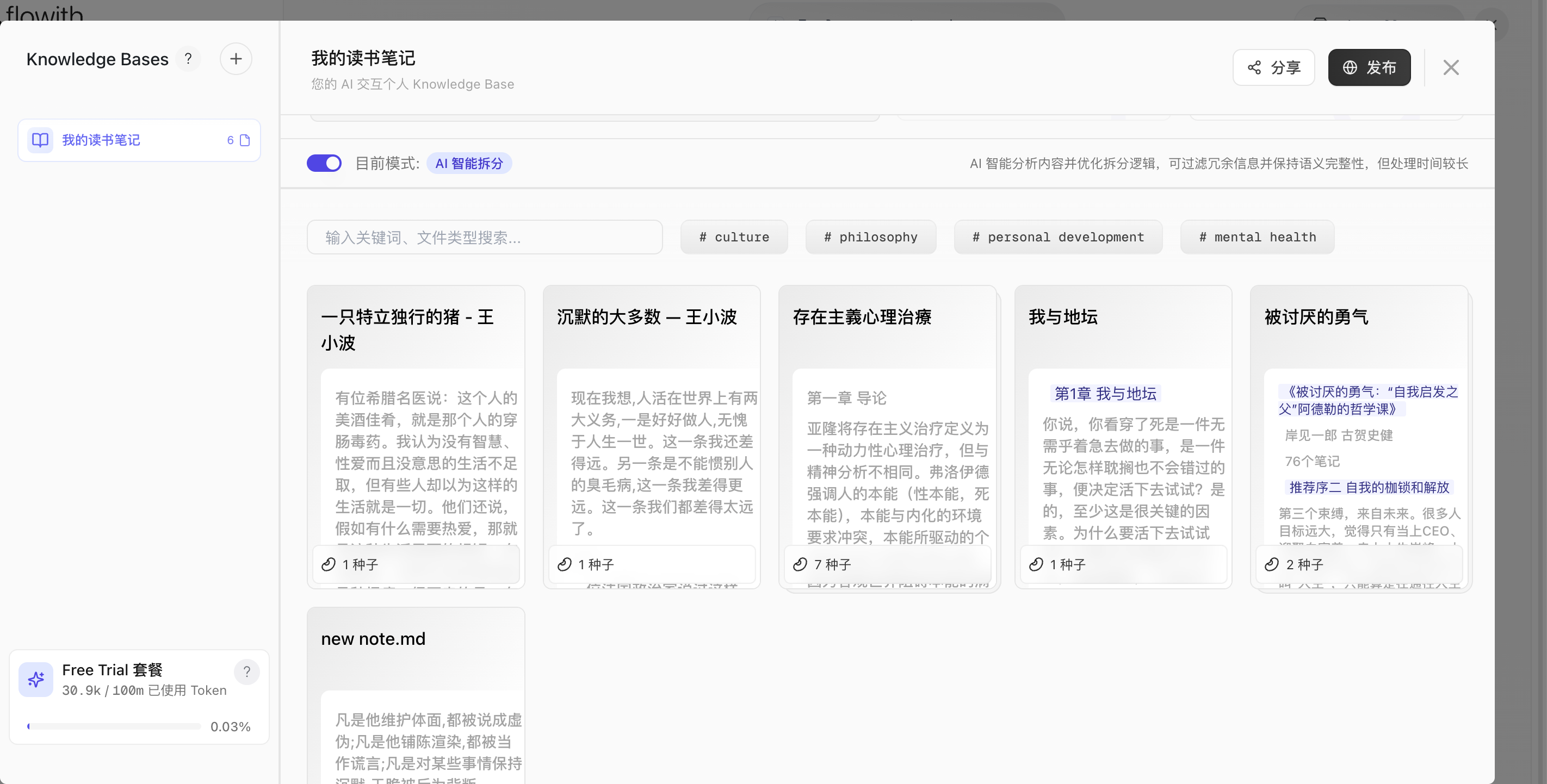 | - 会自动把文档打上标签 \#心理健康- 种子:类似于切分的知识块 - 缺点:切分的非常非常粗糙,比如《存在主义心理治疗》那篇,有三万多个字,但是只切分了 7 个知识块。 - 但是知识块的切分质量是直接影响到问答质量的,我会觉得这个产品的知识库问答效果不是那么好 - 比如一个知识块最多 2000 字,自动解析后已经 4000 多字了  |
| 查看、编辑知识块 | 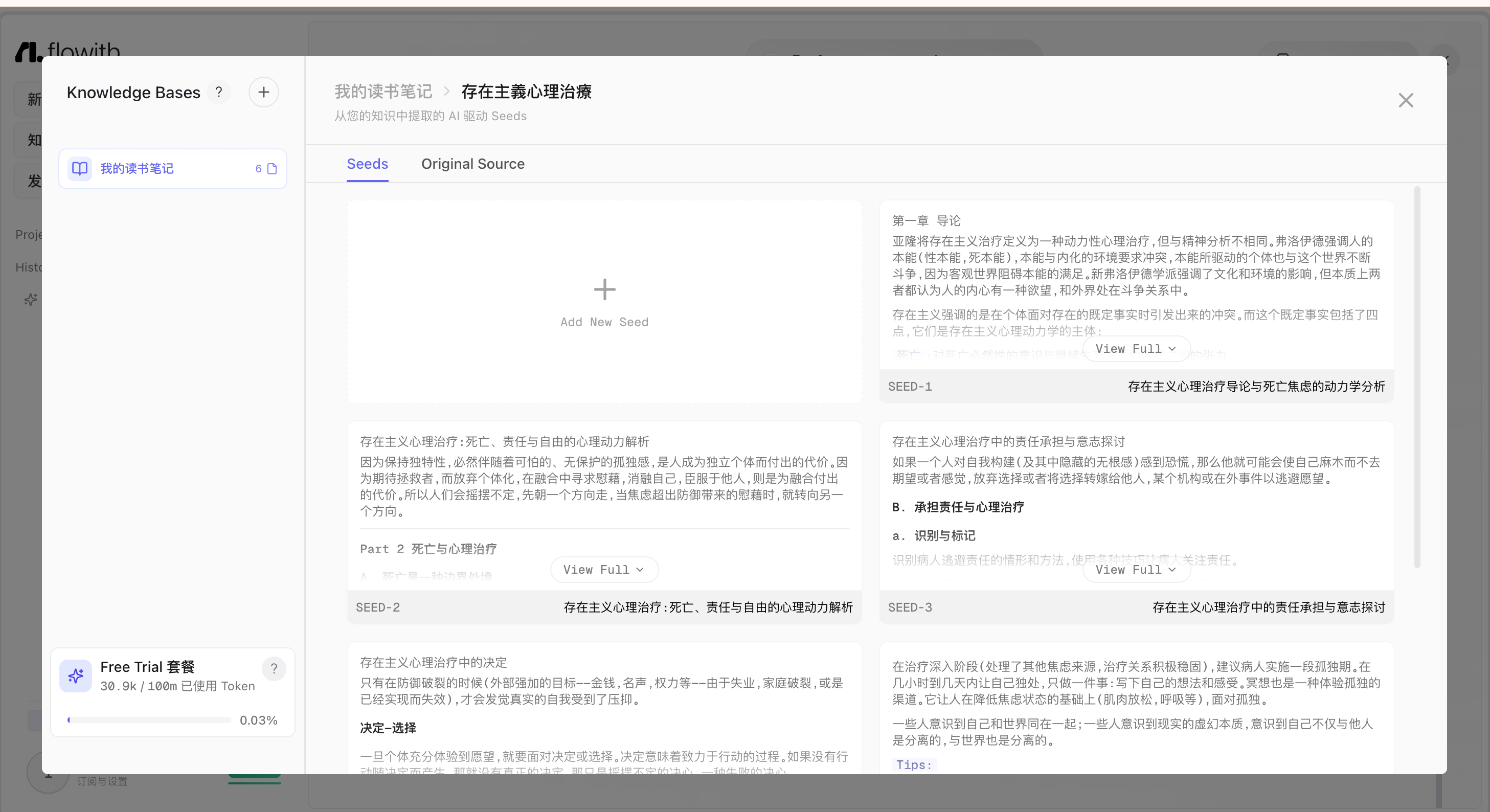 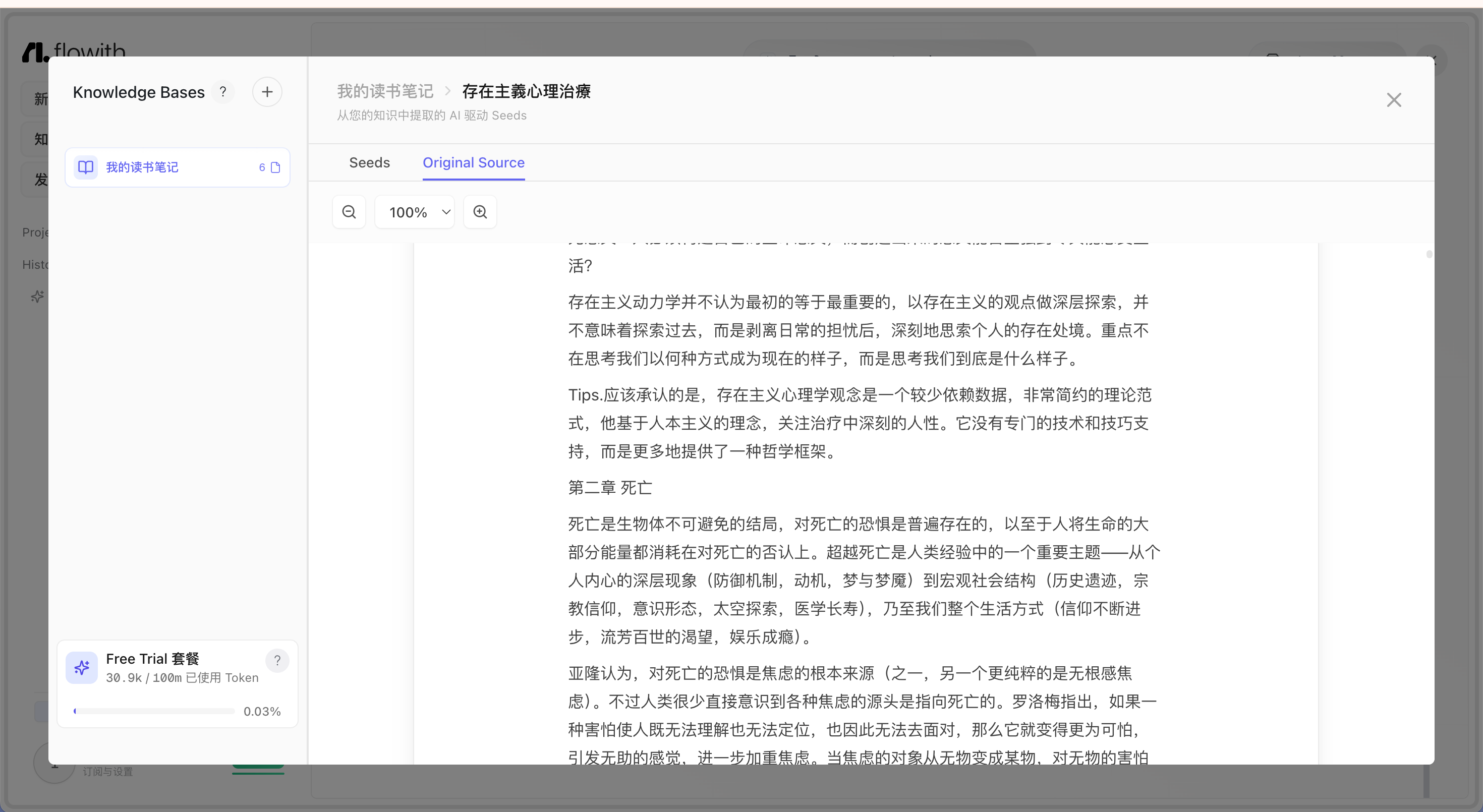 | - 某个文档点击后可以查看“种子”及原文 - 可以手动添加知识块  - 也可以针对知识块进行编辑和删除  |
| 分享 |  | - 分享:获得链接的人可以阅读这个知识库 |
| 发布 | 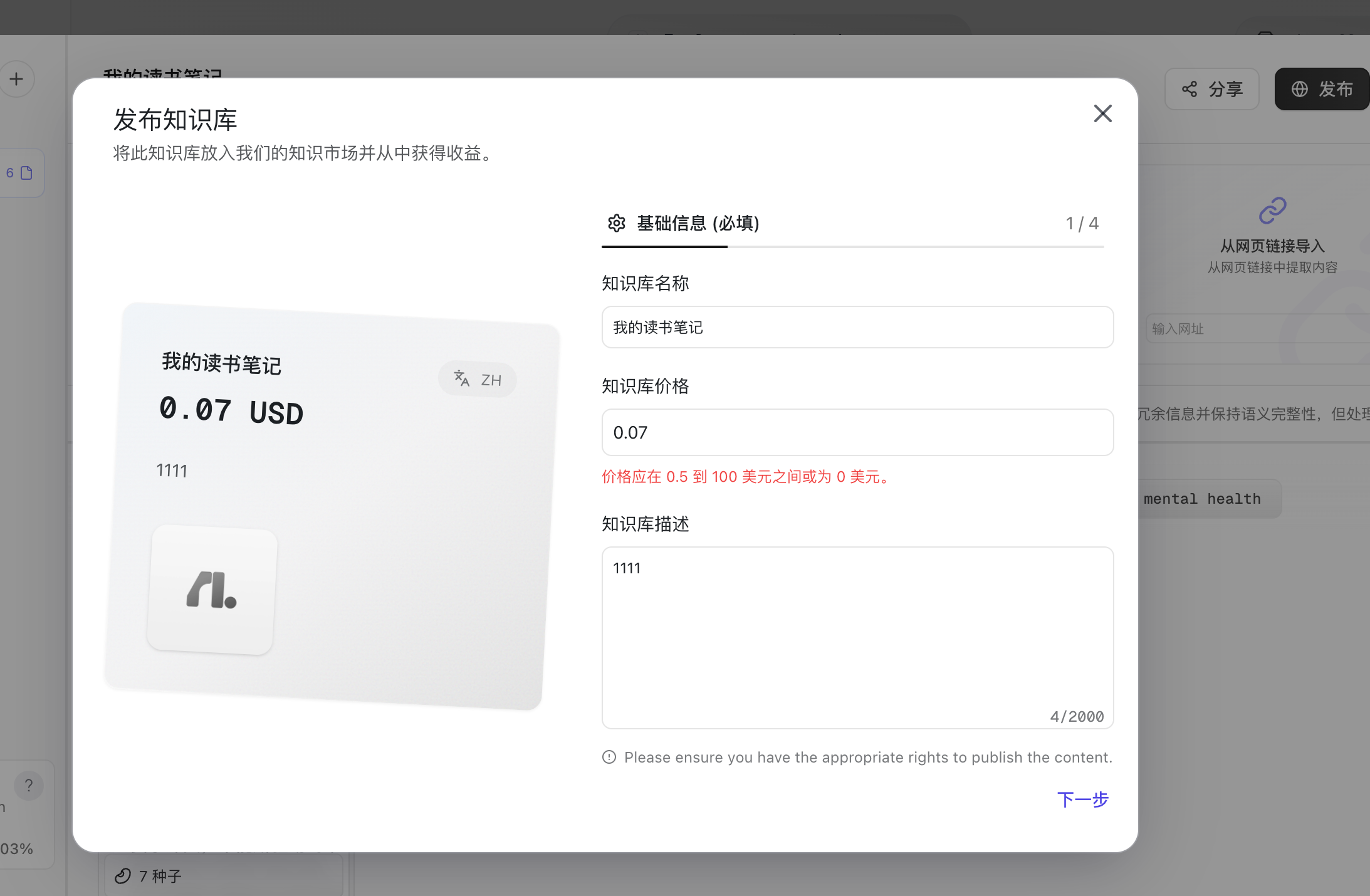 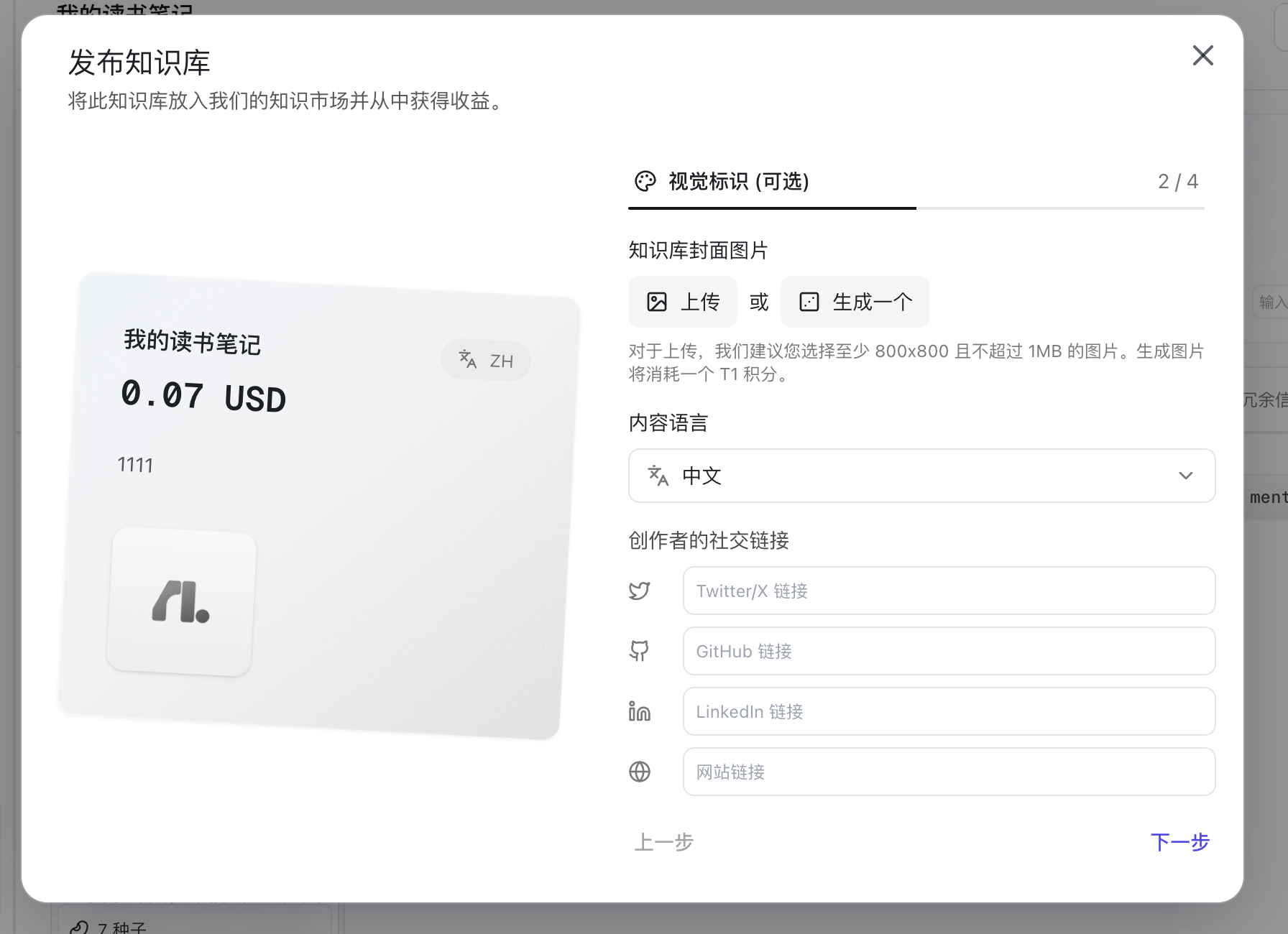 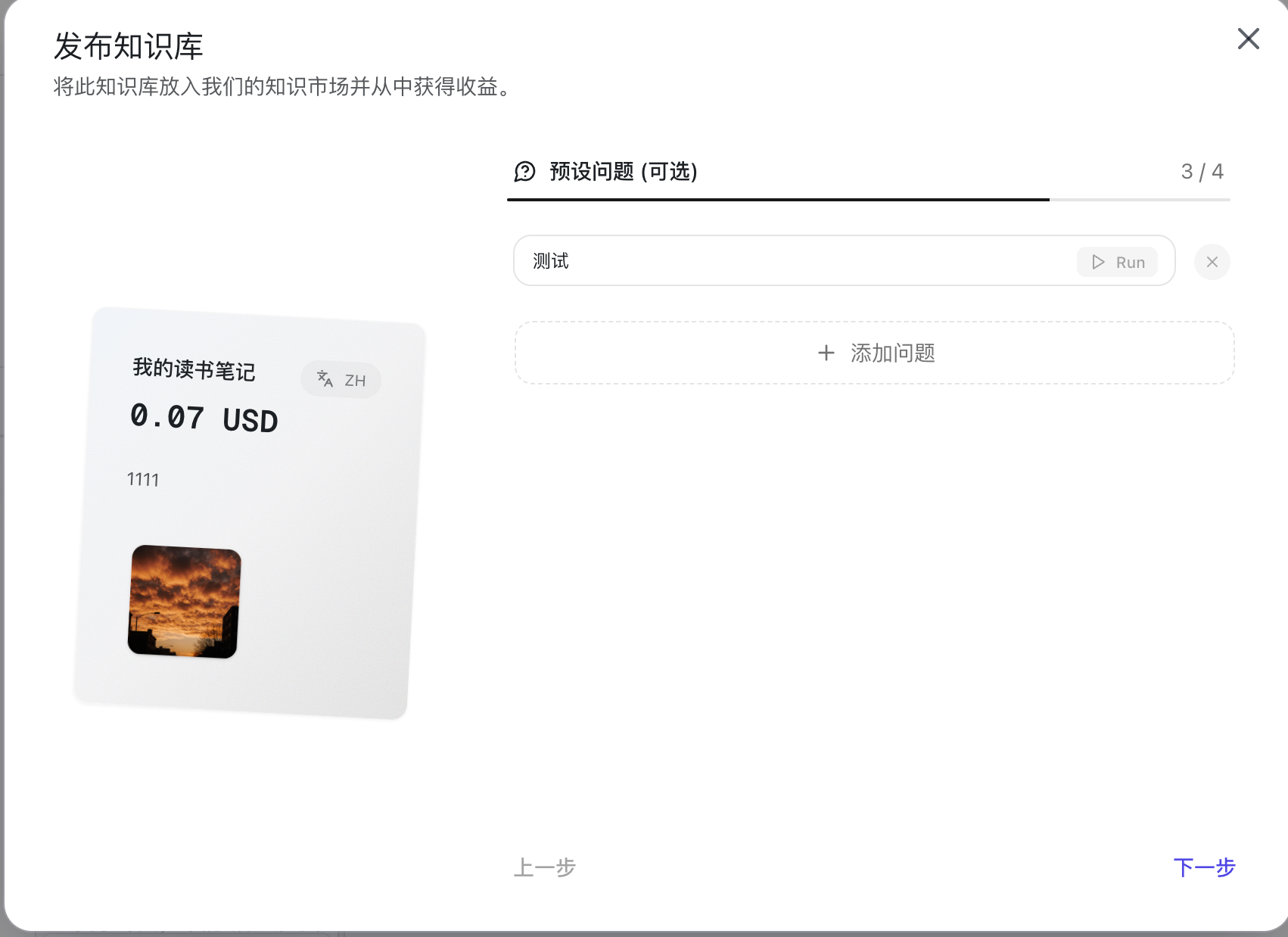 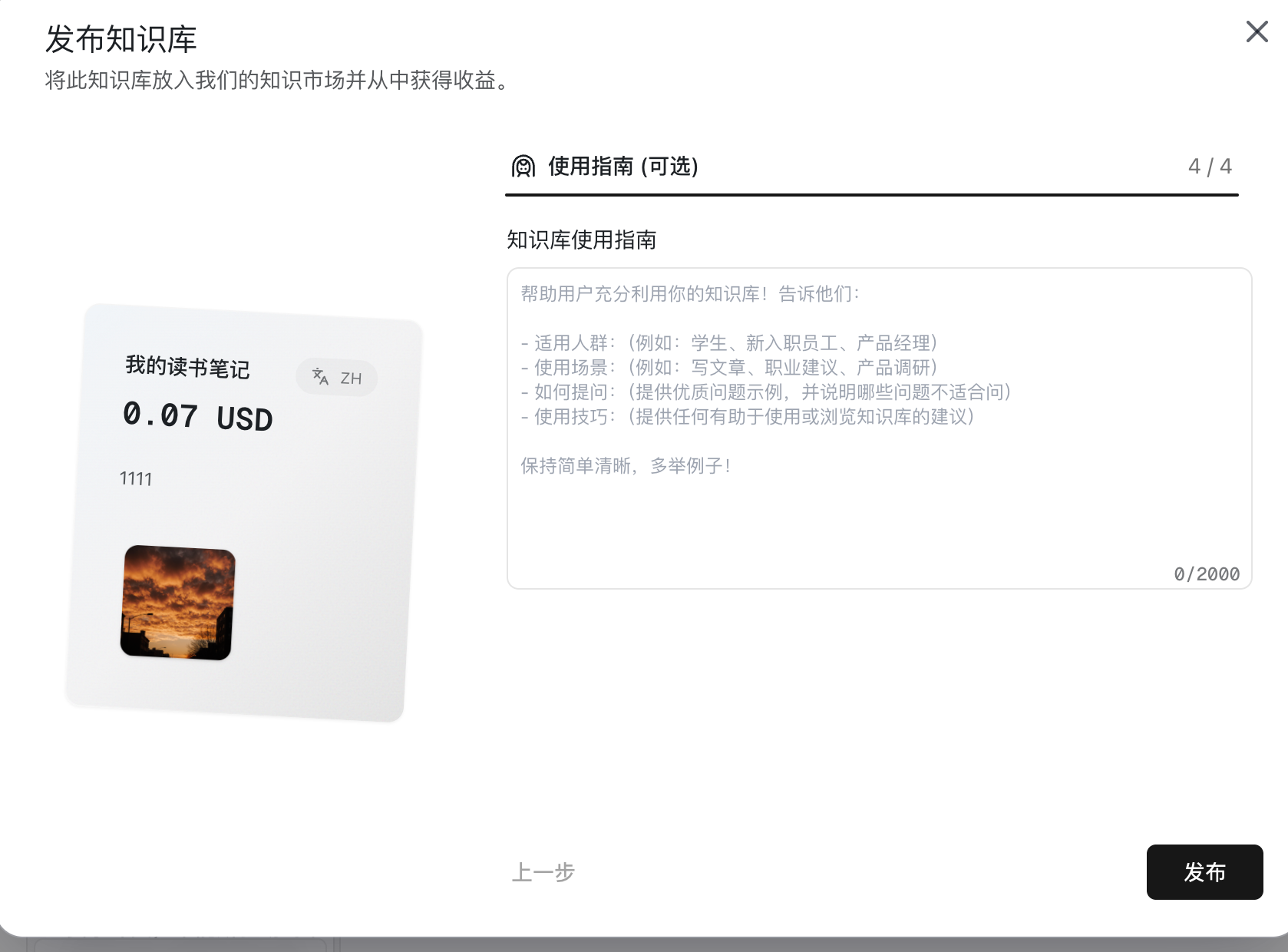 | 1. 填写知识库名称、价格、描述 2. 增加封面、相关链接 3. 增加预设问题 4. 增加使用指南 发布出去后可以赚钱 - 还可以通过 API 的方式在其他地方调用 |
| 问答时引用 | 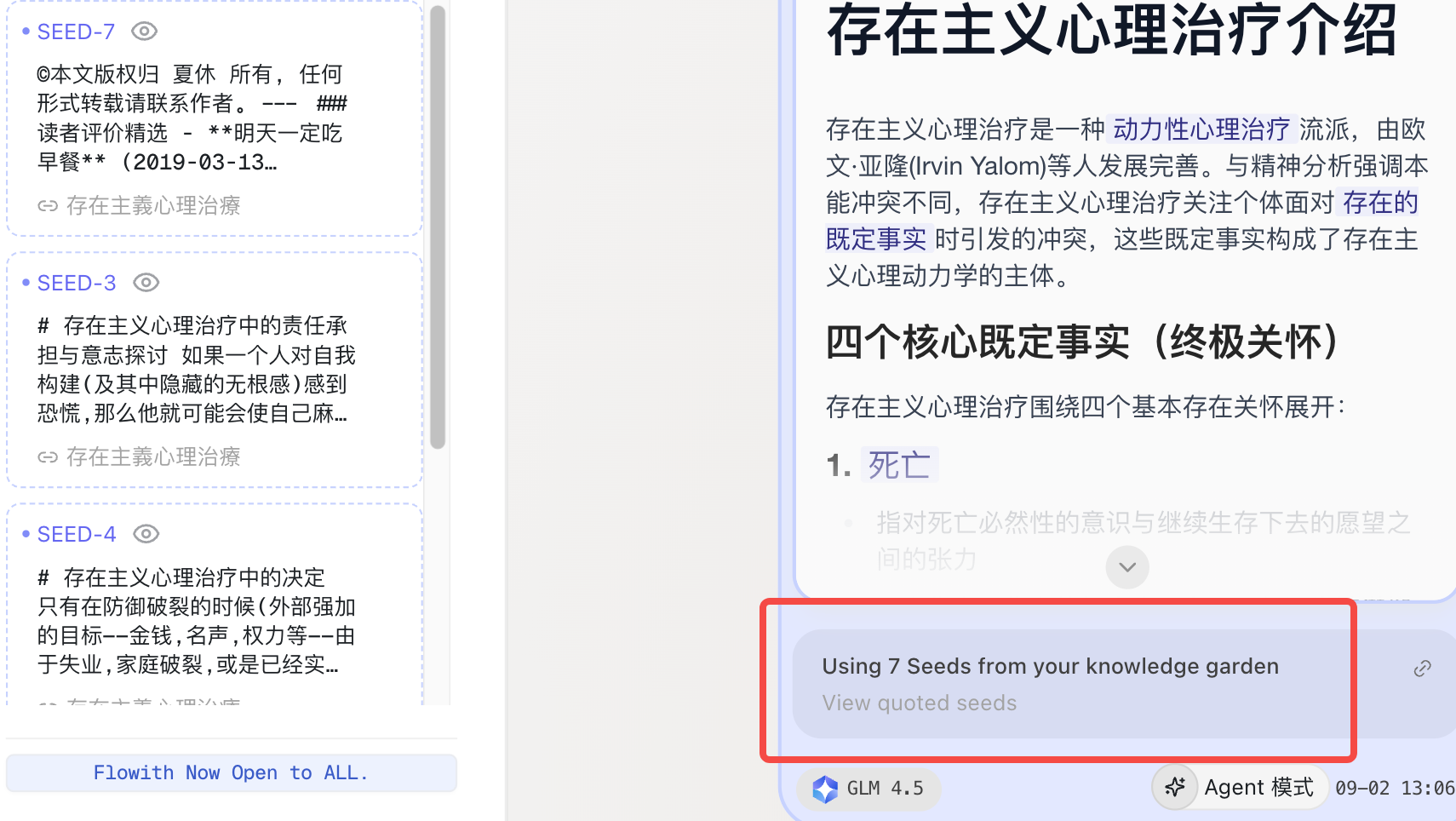 | - 每个节点都可以看到引用的知识块 |
发现更多
知识库市场
| 步骤 | 截图 | 说明 |
|---|---|---|
| 知识库市场 | 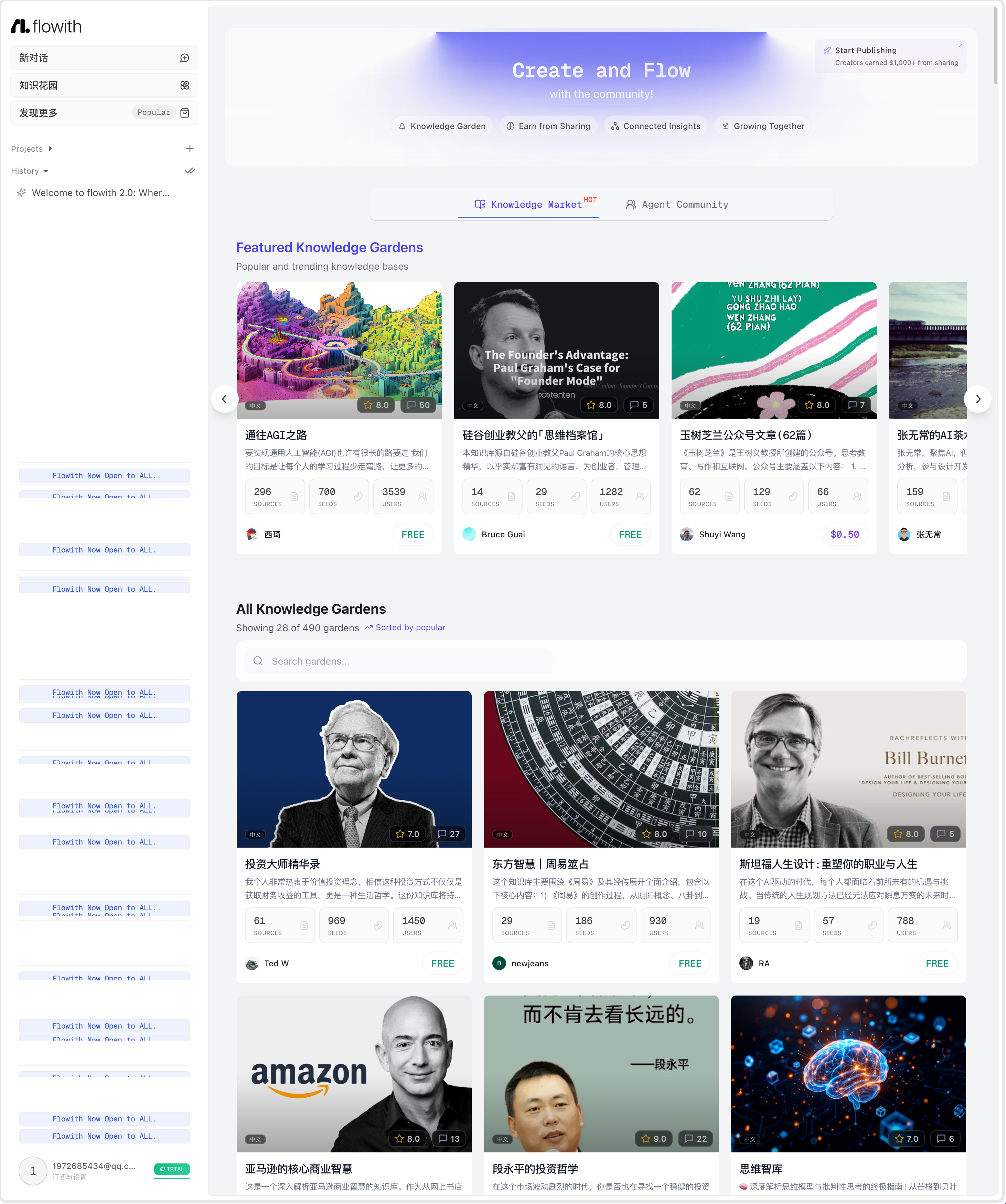 | 点击每个知识库的卡片,会进入到知识库的详情,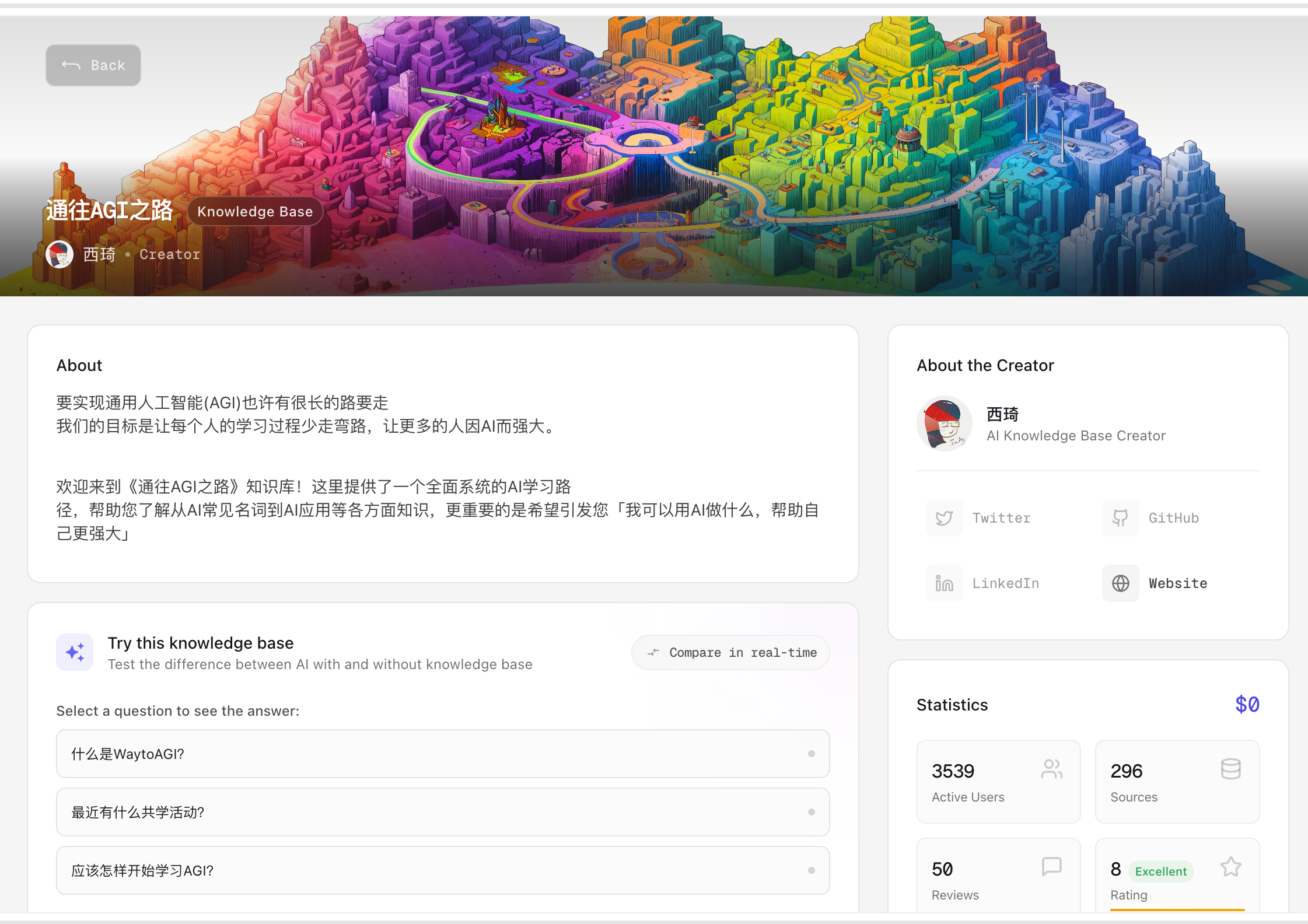 - 引用知识库 VS 不引用知识库 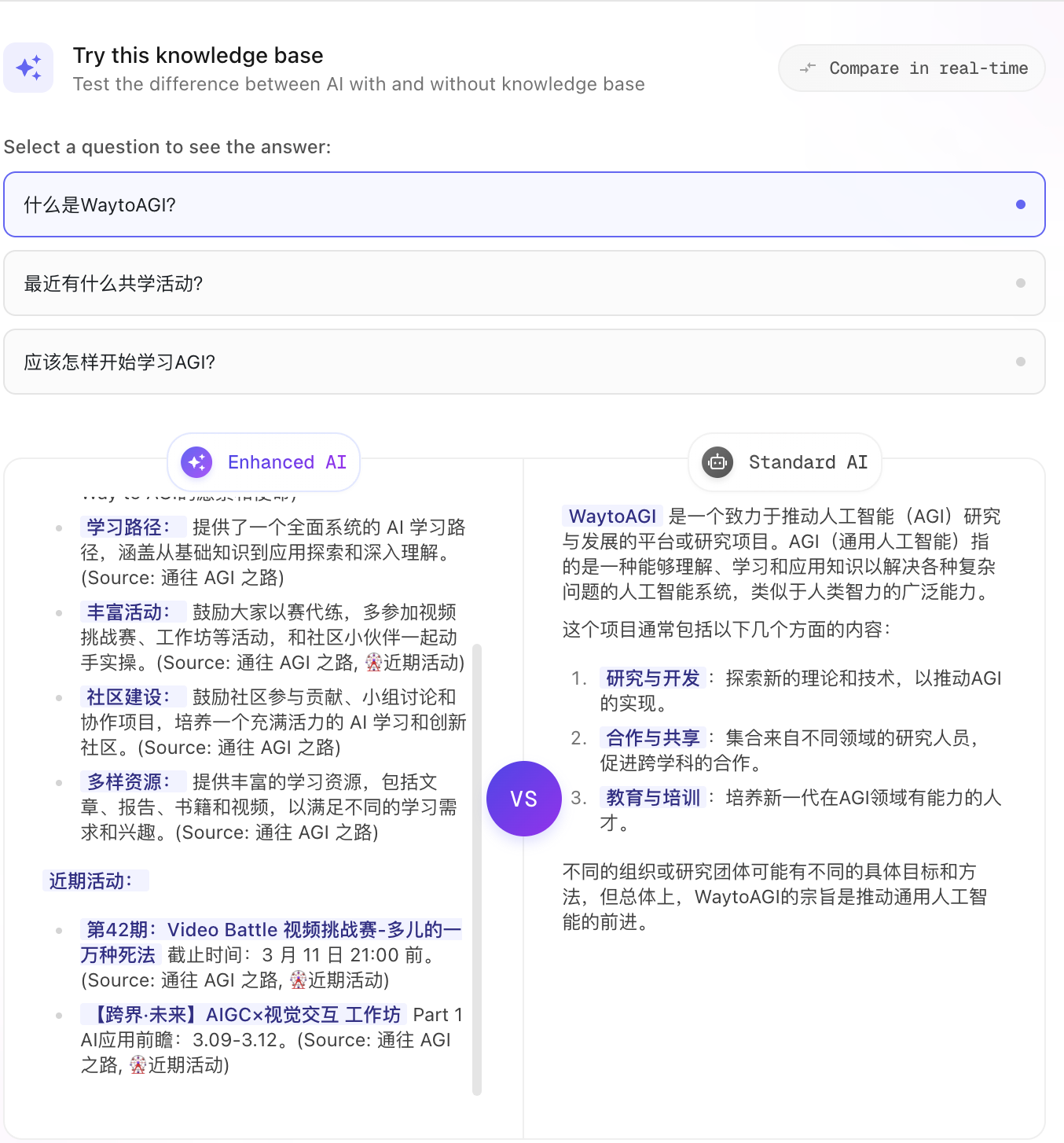 - 使用建议、评论、数据概览 |
| 添加到我的知识花园 |  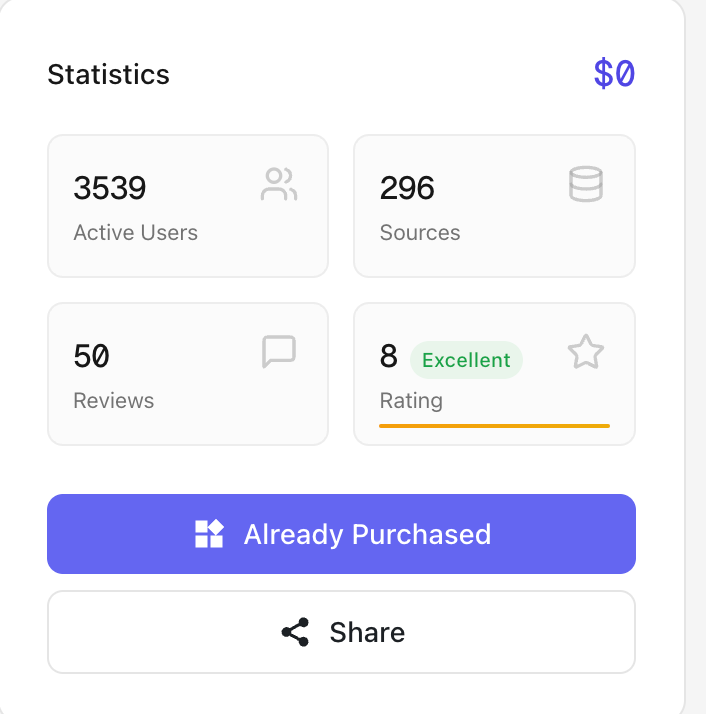 | 添加后可以在问答时引用这个知识库 付费知识库需要支付后才能添加 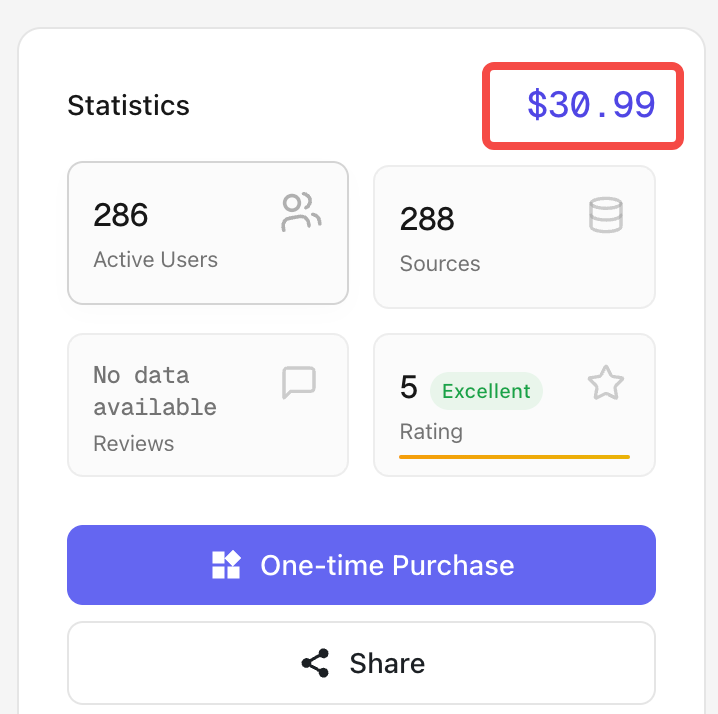 |
agent 社区
| 步骤 | 截图 | 说明 |
|---|---|---|
| agent 社区 | 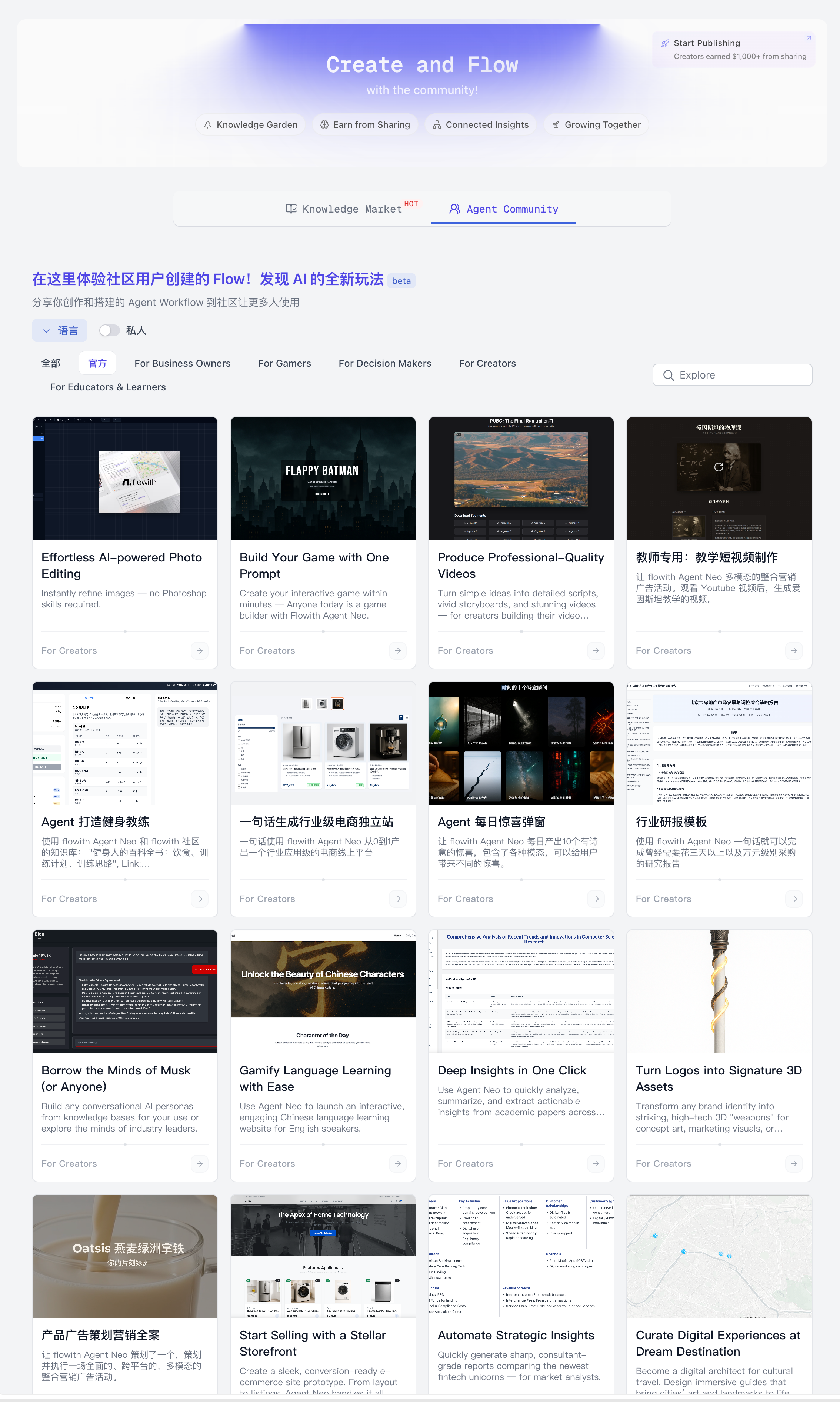 | 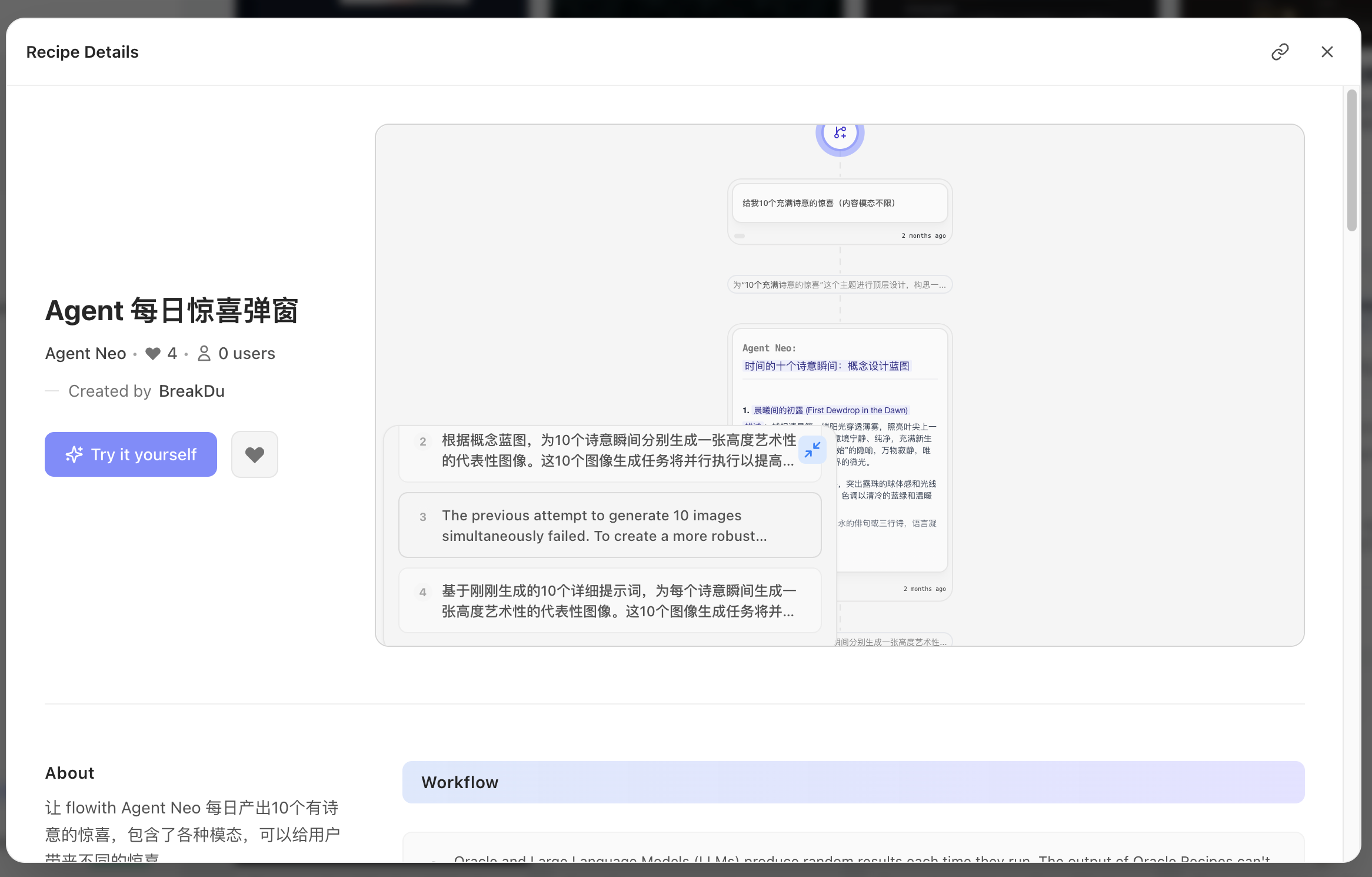 智能体的使用视频,可以直接套用这个例子 |
非 agent 模式
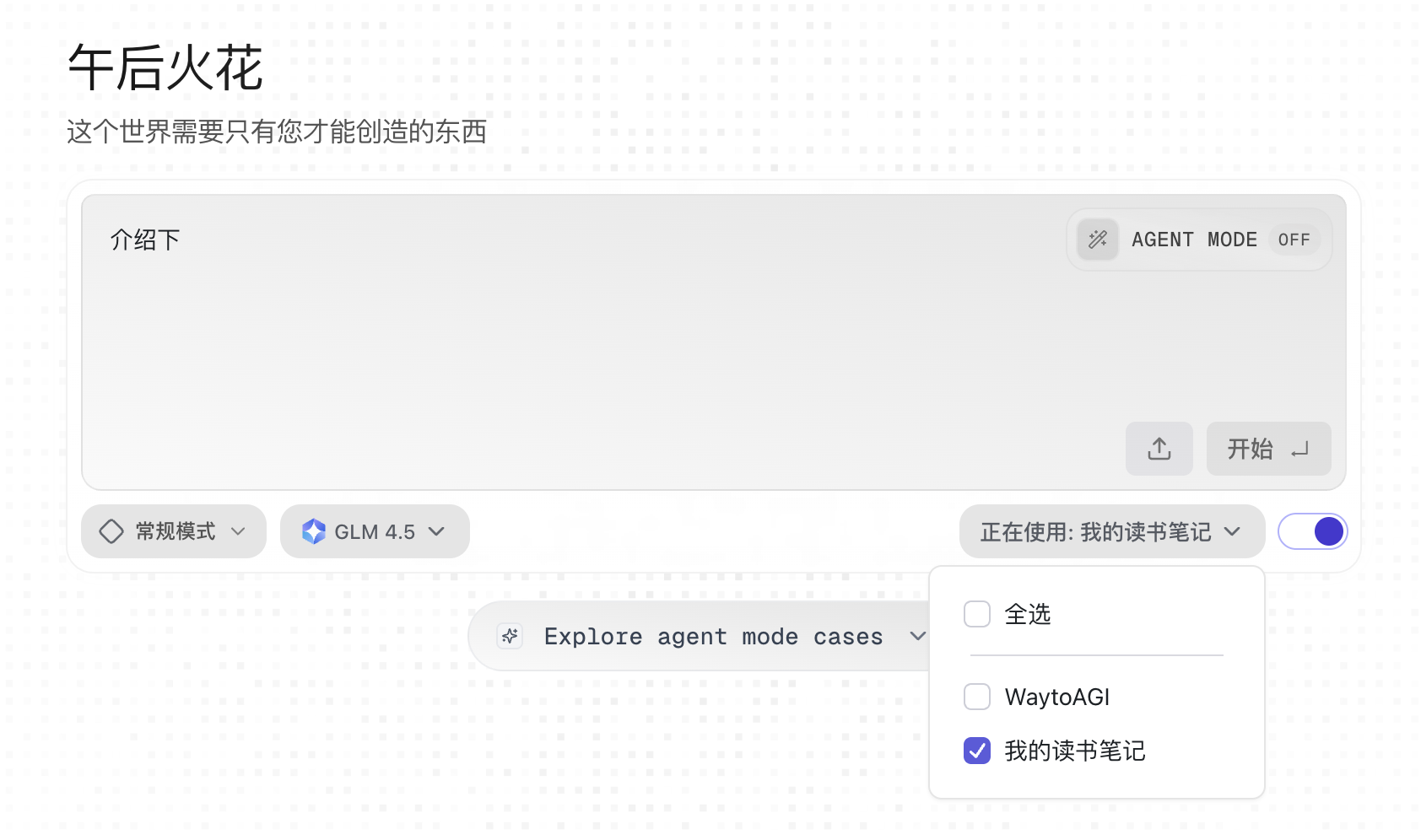
常规模式
使用知识库-RAG
可视化展示引用的知识块
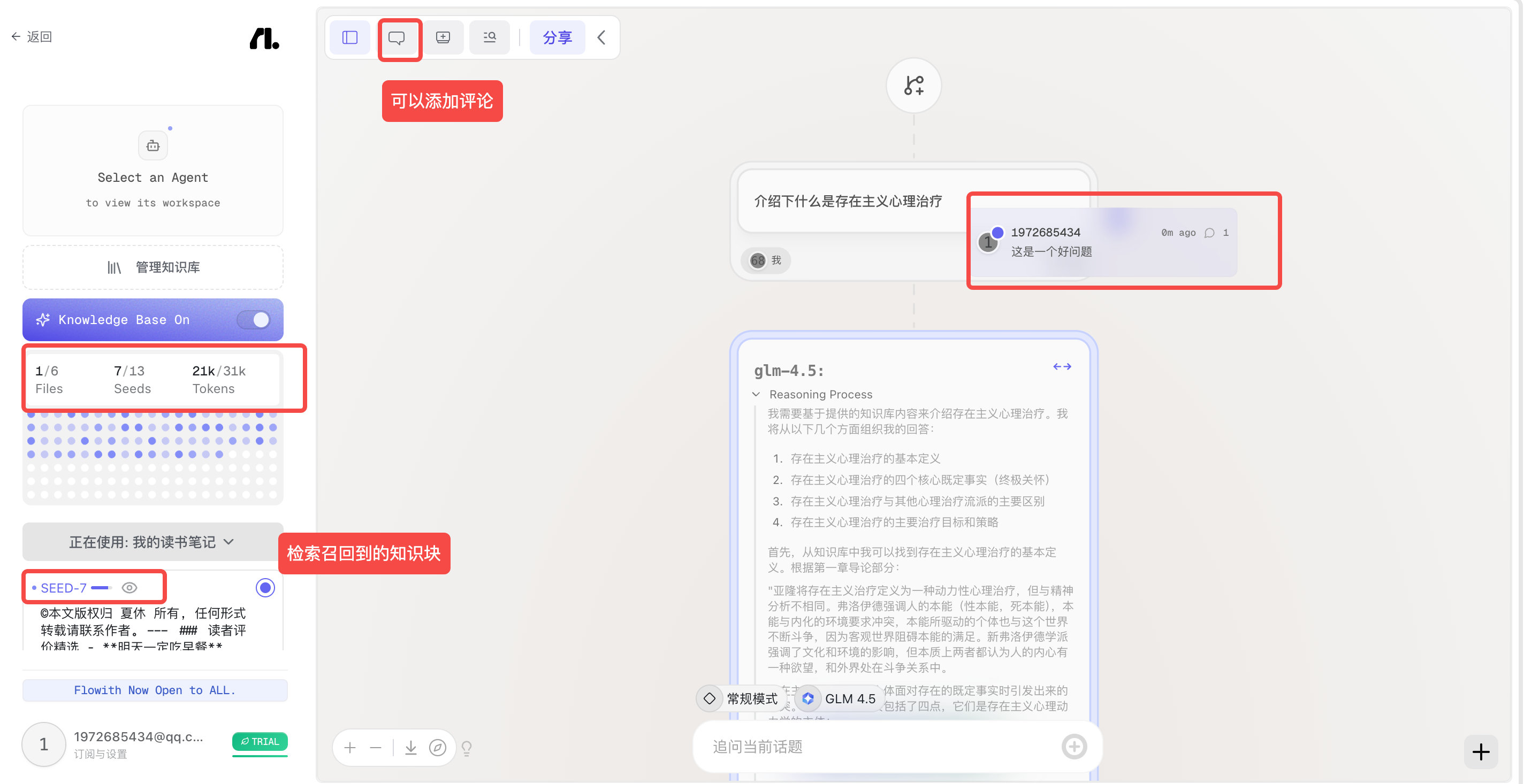
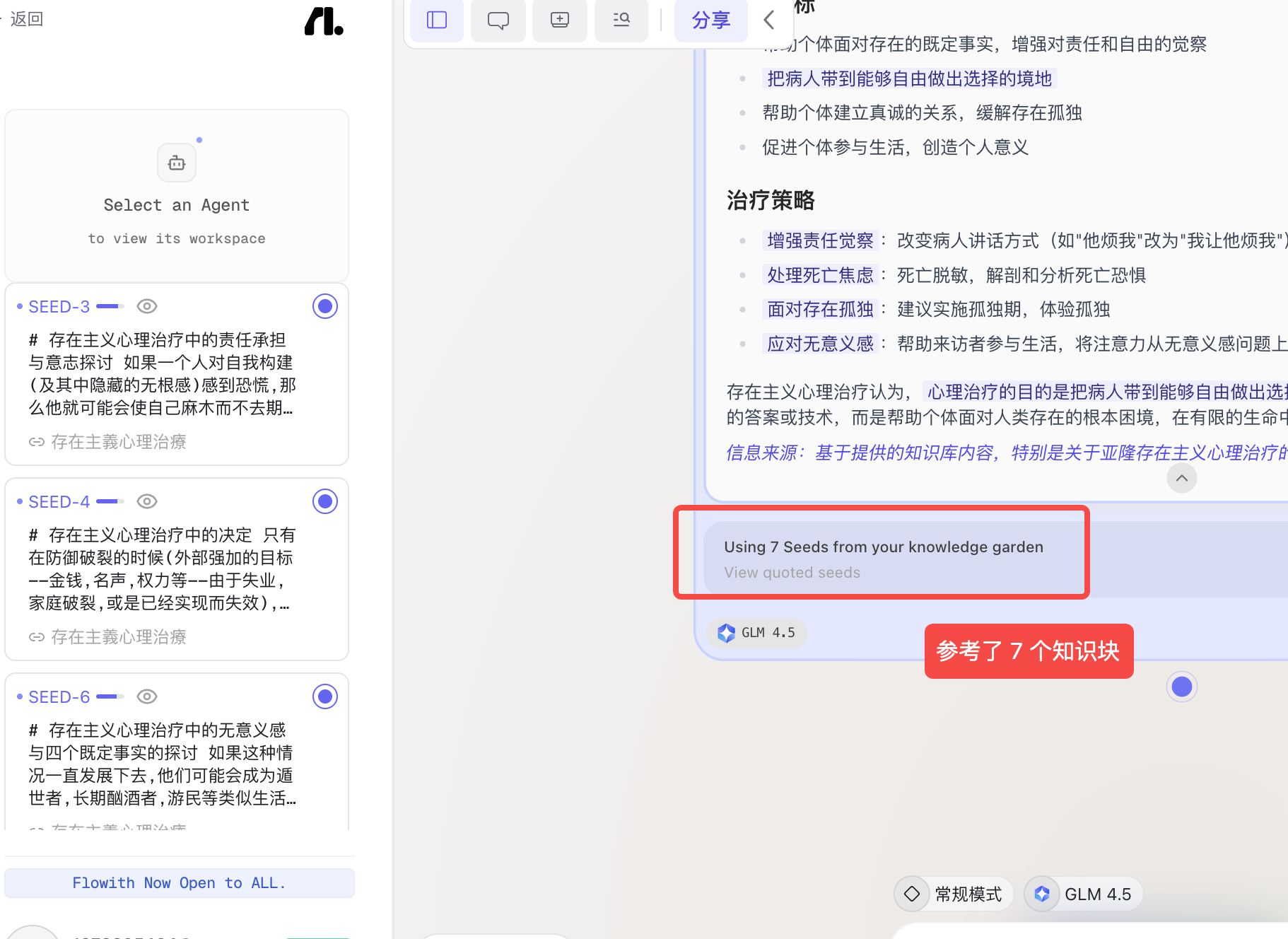
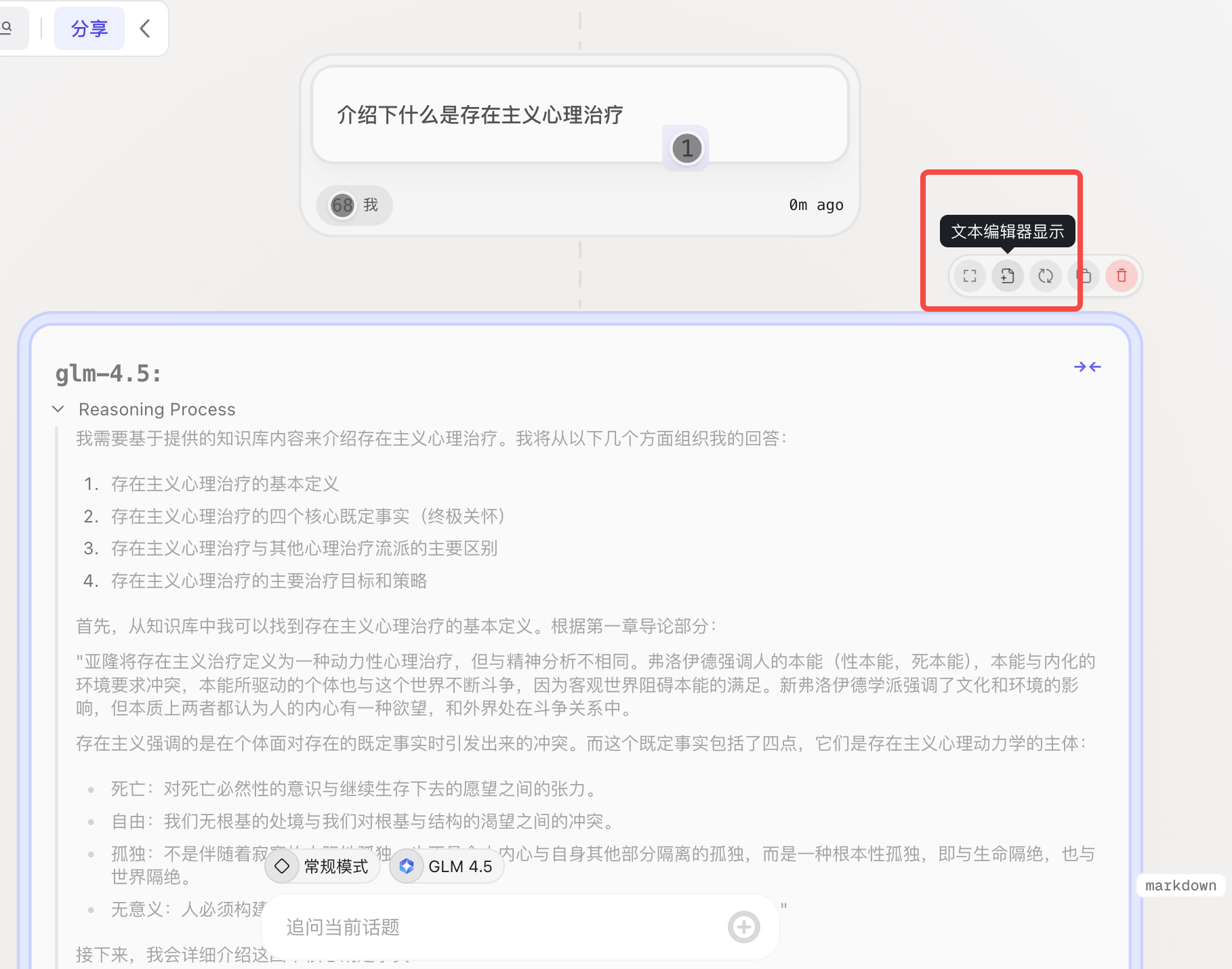
在 markdown 编辑器里编辑
在编辑器里修改编辑、复制、导出为 PDF
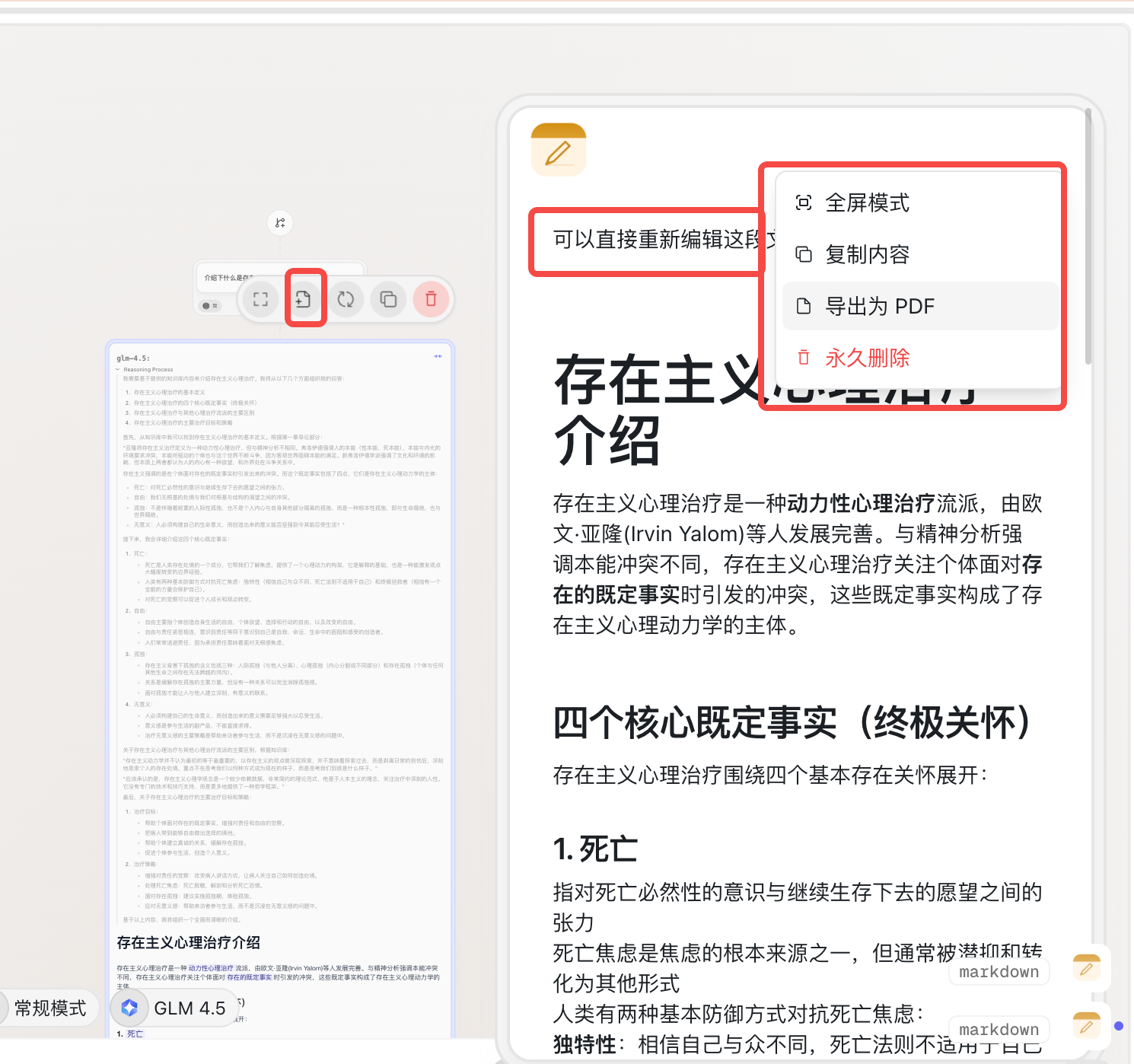
任意开启新分支、选择不同的模型
适用于在一个画布里对比不同模型针对同一个问题的表现
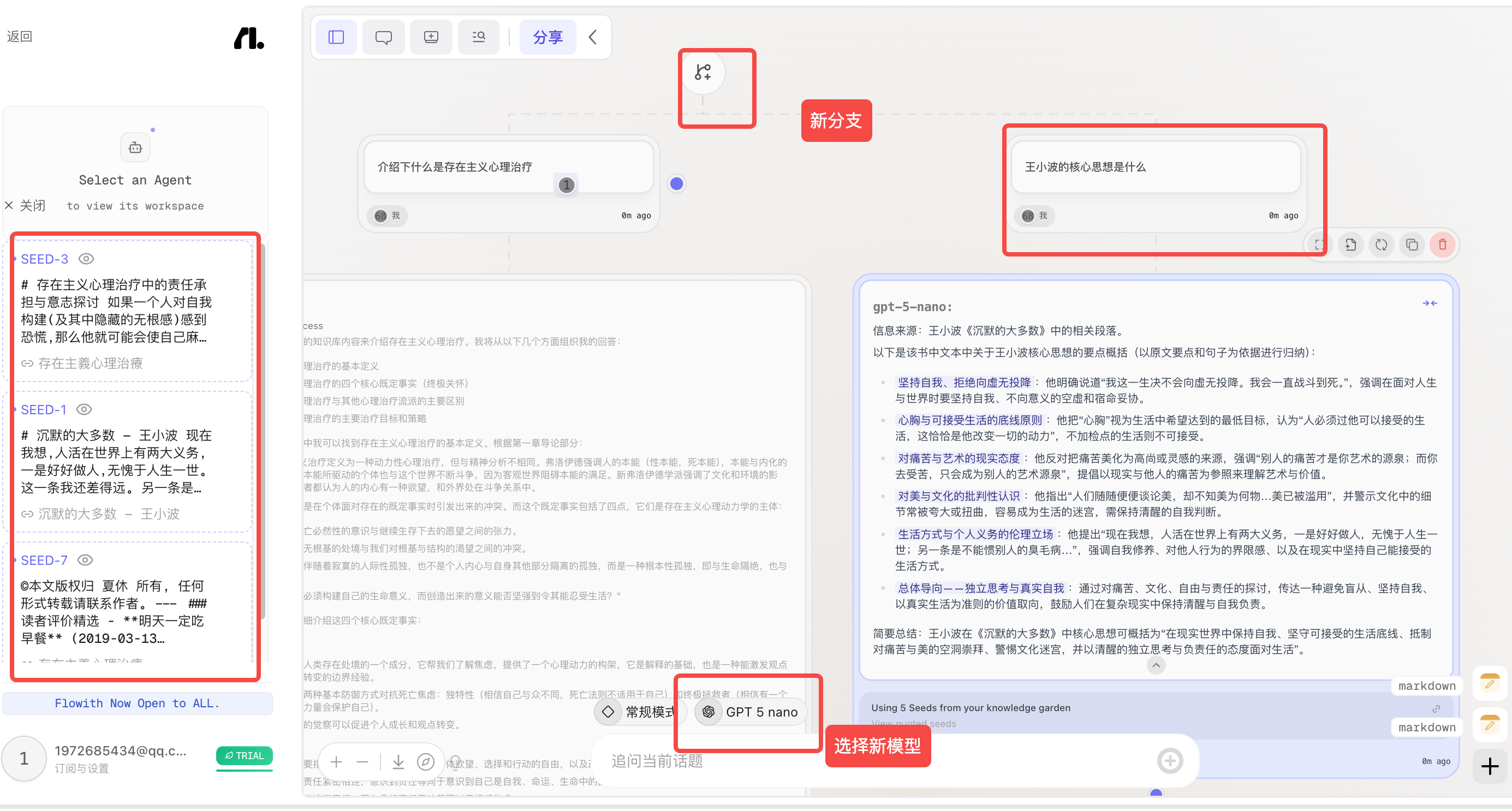
引用其他节点的内容
可以灵活参考不同分支节点的答案
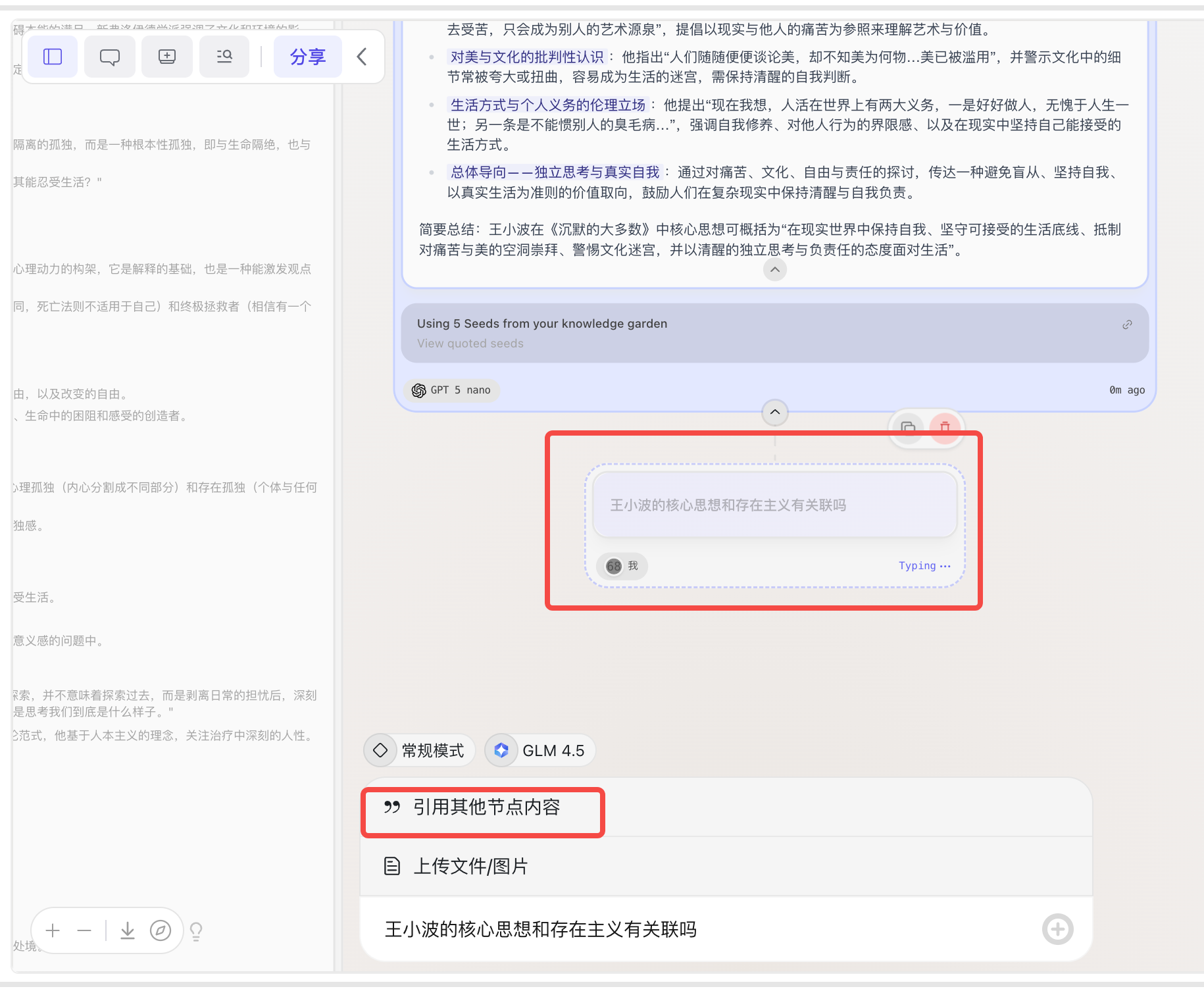
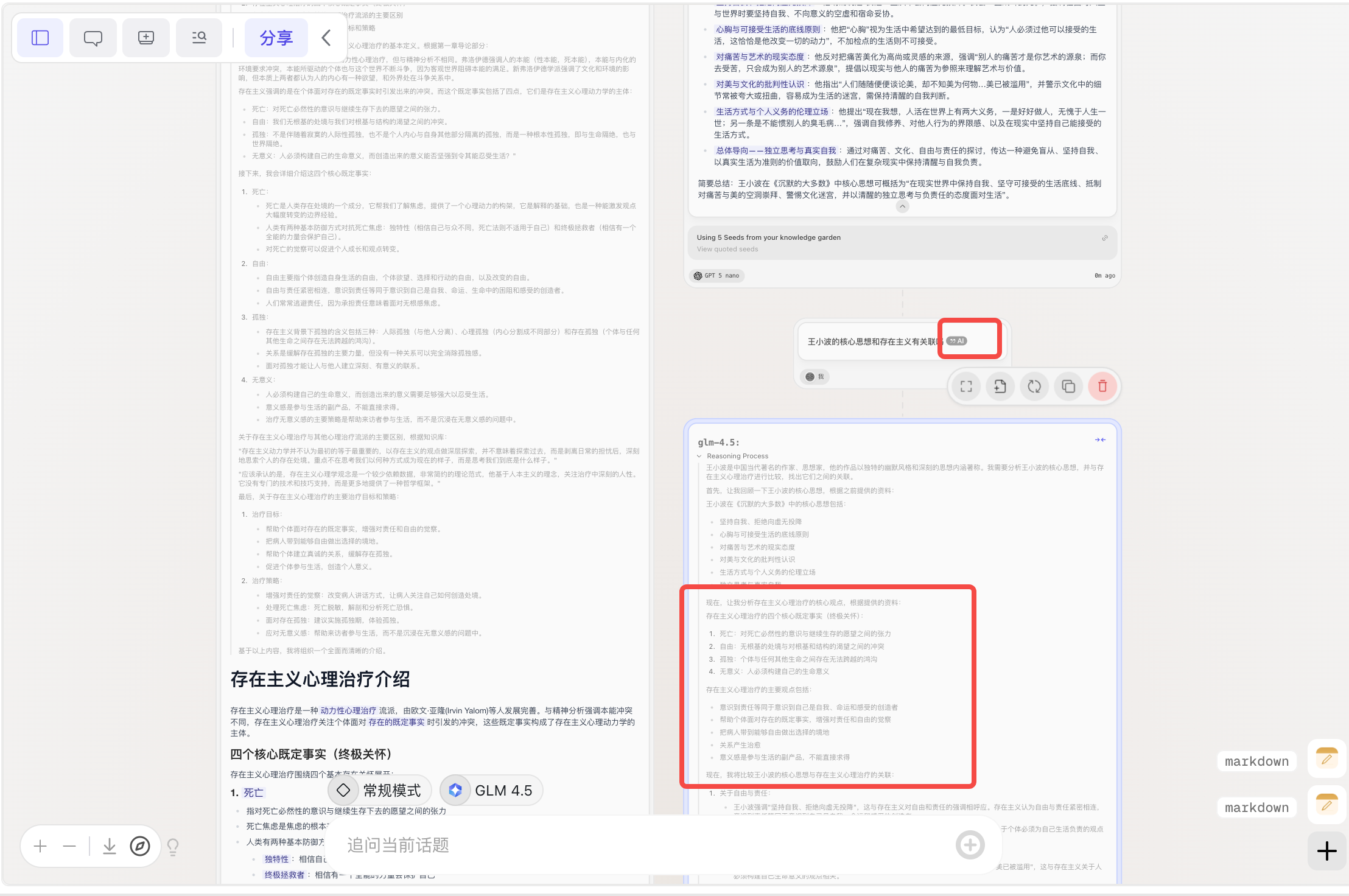
内置编辑器
-
Markdown文本编辑器、图片编辑器、代码编辑器
-
实时语音对话
- 图片编辑器:相当于新增了一个图片节点
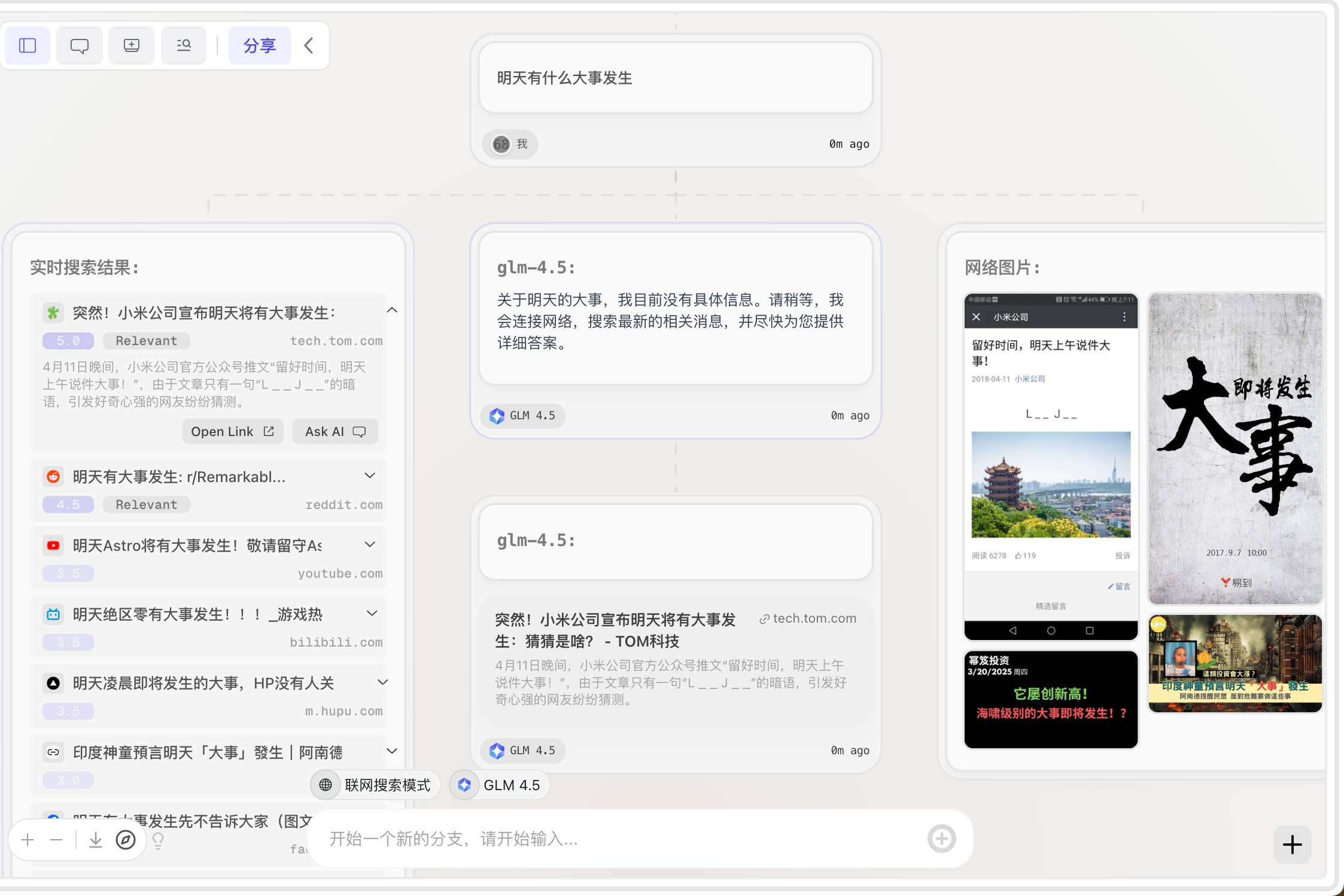
联网搜索
-
联网搜索信息,筛选后,给到大模型做总结输出
-
网页链接、大模型输出、网络图片,分成三条分支
-
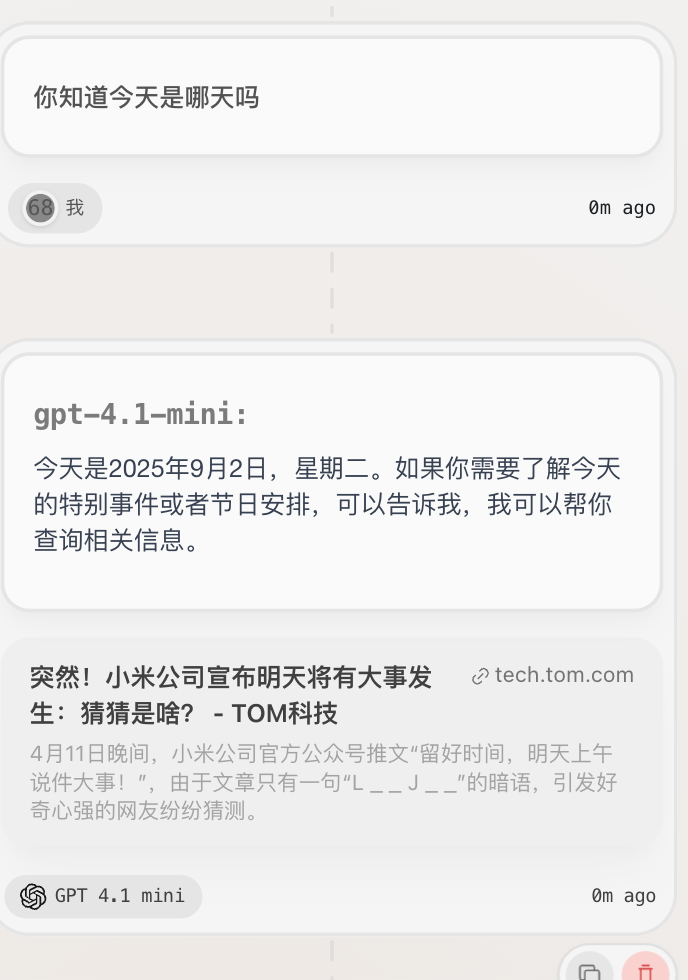
缺点:联网搜索的时效性很差,flowith 也没有做相应的优化。引用的那条信息源是 2018 年 4 月份的。对比 GPT 的结果:
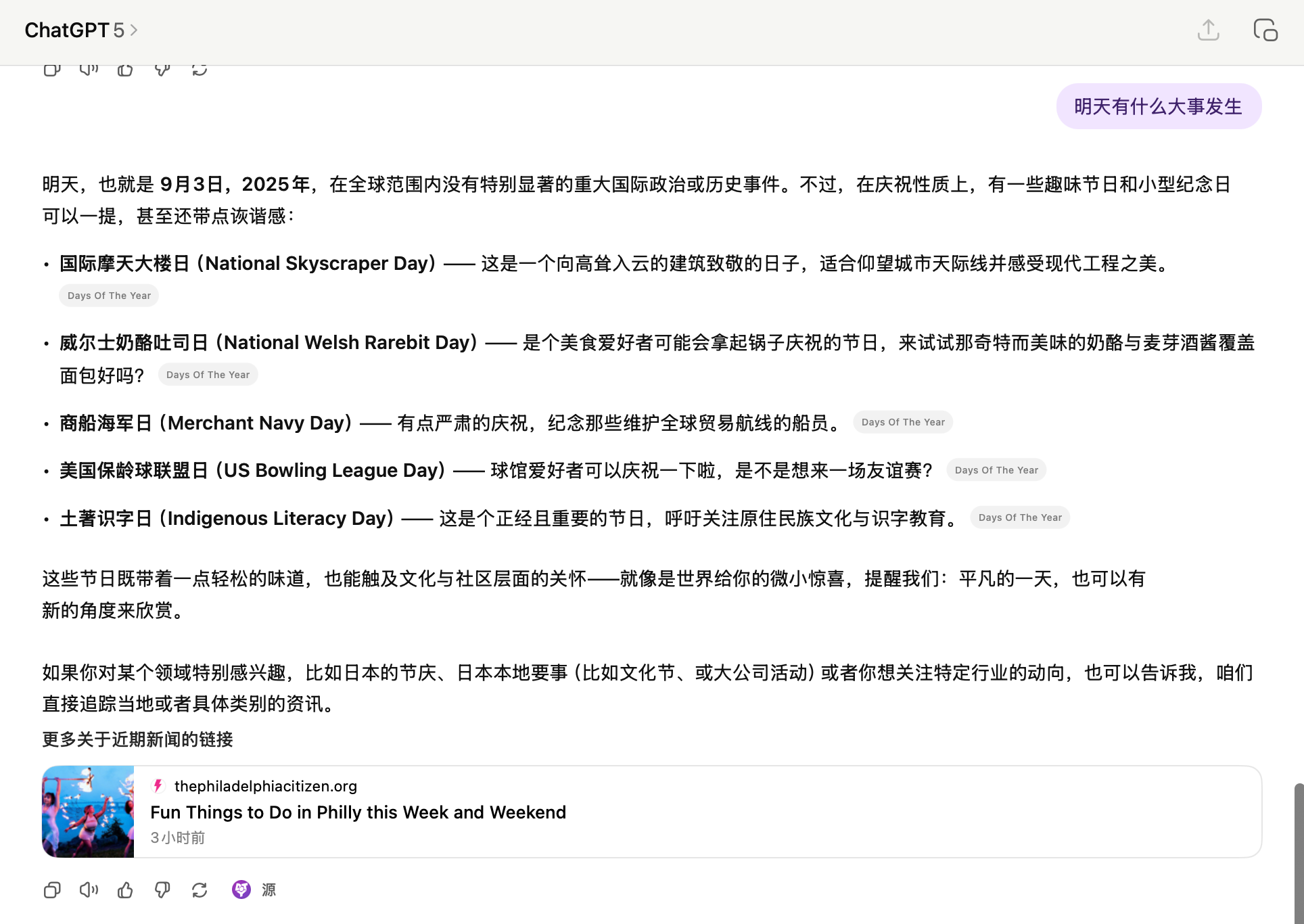
图片/视频生成
- 有很多模型可选择:
- 但是有 bug,输入完提示词发送后,提示词内容变空了,而且一直报错
提示词生成
-
使用 AI 来优化原本的提示词,该模式下会自动切换到 claude 的模型
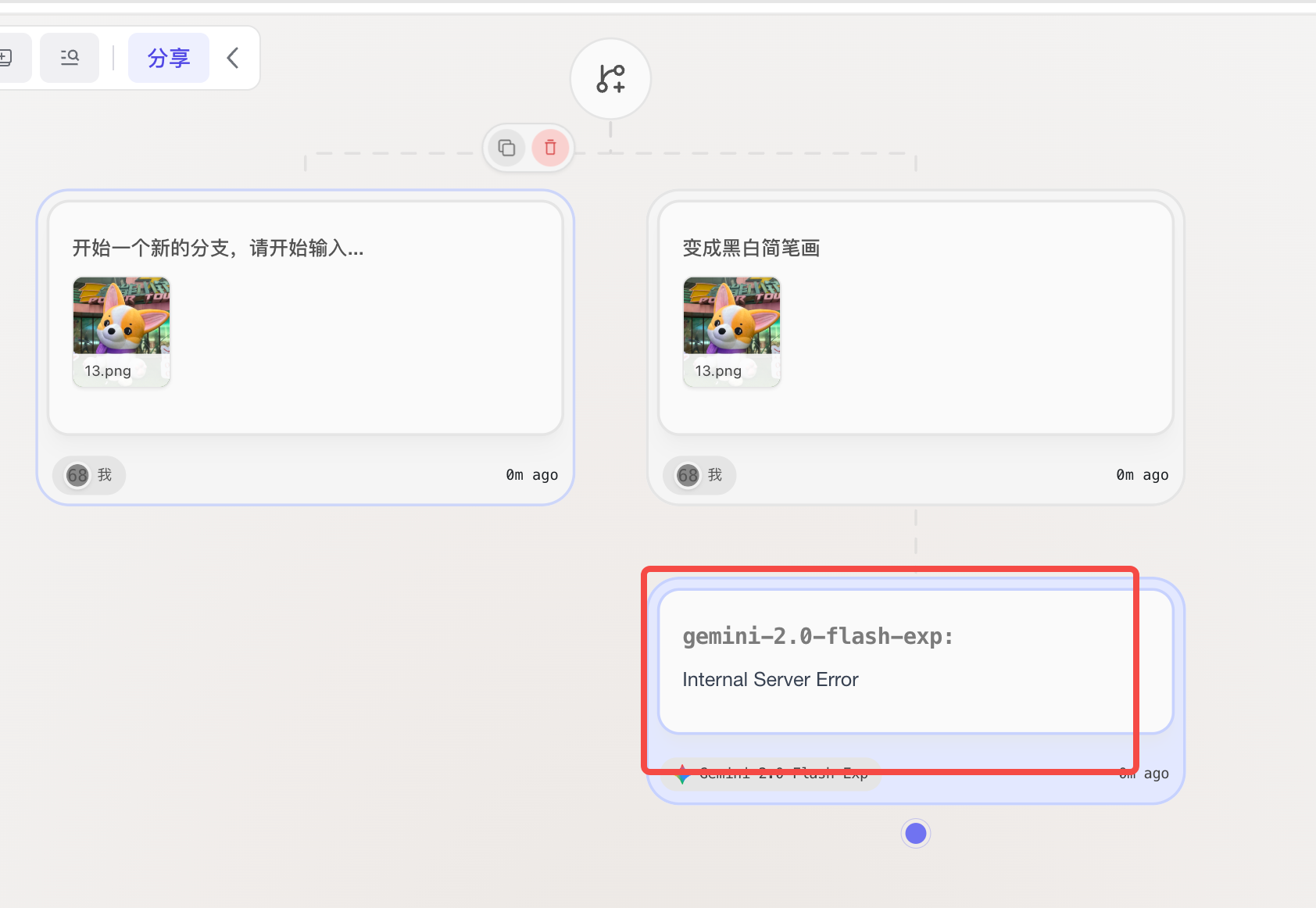
-
有明显 bug:输入内容点击发送后,内容不见了。重新输入后也没有什么输出
比较模式
- 选择多个模型,同时回答同一个问题
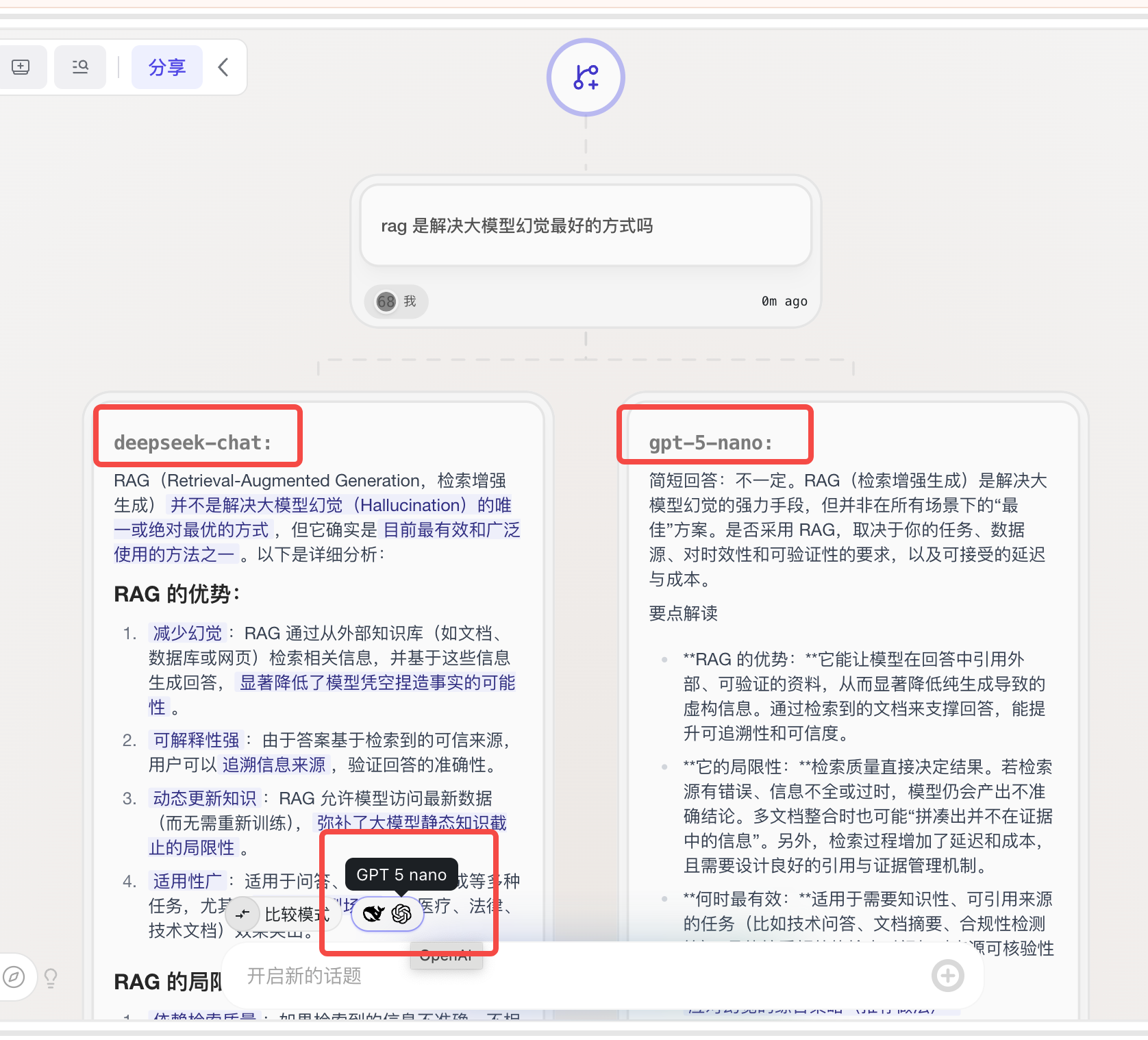
agent模式
这是由 flowith 团队开发的最先进的、以通用人工智能(pre-AGI)为目标设计的的智能体系统,专为处理多步骤、复杂、需要使用更多工具的任务而设计。
它的功能包括自主规划任务、任务分解、无限制工具使用和自我优化。Oracle 的外部能力会不断更新和升级。使其随着时间的推移变得越来越强。
换句话说,Oracle is a data-level(数据层级别的、而不具备物理介质或和现实世界交互的)generalized (可以完成通用的任务、而非只有他被训练、或定义过的任务) Agent(不只是 LLM,可以调用工具、管理记忆、多 LLM 协作) that can complete complex tasks (不只是完成简单的问题或命令)and adapt to new situations(在新的环境或任务下可以自我学习和处理).
核心概念
- Recipe 工作流
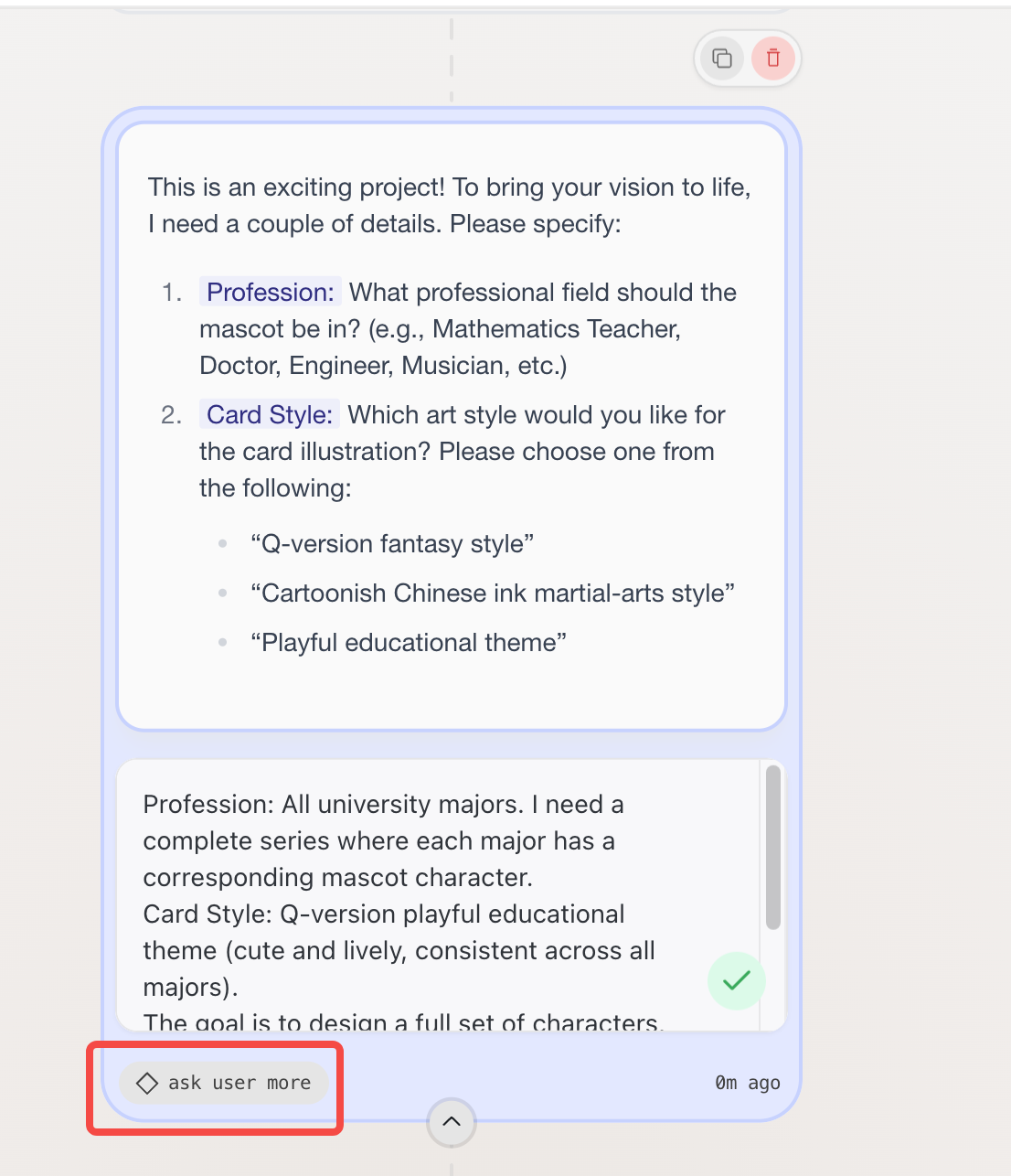
Recipe 一词原意是指配方、烹饪方法。对于 Oracle 来说,Recipe 是指 AI 在去完成用户任务时,去执行的一套系统性工作流。当每次用户输入完需求或指令,Oracle 都会整体的指令进行拆解,根据它自身的能力和可调用的工具,把整体任务拆成一步一步自任务,然后再交给任务分配器去一步步执行。
在每次 Oracle 设计完一整套 Recipe 后,它都会与用户确认,随后才开始执行,用户在确认过程中可以直接修改 Recipe 里的具体执行步骤,包括调整顺序、删除、修改文字和增加新的步骤。
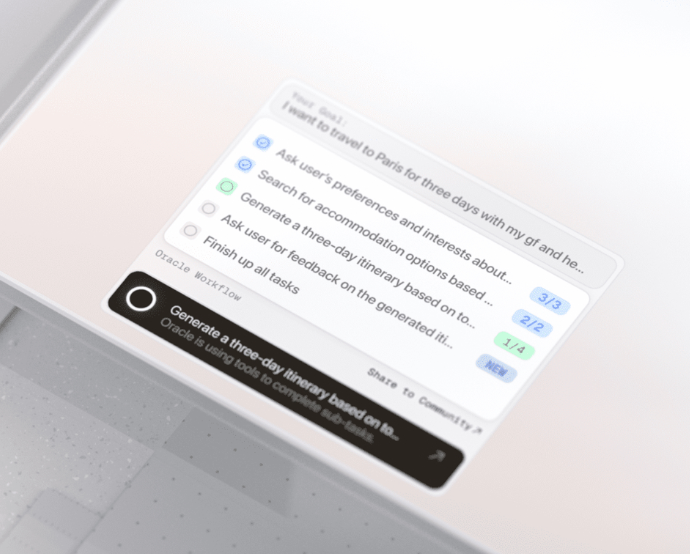
A Recipe Generated by Oracle
- Dispatcher 任务分配器
任务分配器是指每一条 Oracle 生成的自任务在被执行时,会有一个分配任务的 Agent 把子任务进行分配和落地执行,它会从 Oracle 支持的工具库里找到最合适的工具,然后把子任务进行执行和完成。
比如,当子任务是 「搜索 flowith 在社交媒体上的用户评价」 ,任务分配器会调用 「Twitter 搜索工具」 、 「Reddit 搜索工具」 、「谷歌搜索工具」 进行对 flowith 用户评价的搜索。
你可以在 Oracle 对话发起页面中查看目前 Oracle 所支持的工具,这个列表会实时更新,我们也将持续把最有用的工具添加到 Oracle 所支持的工具库中。
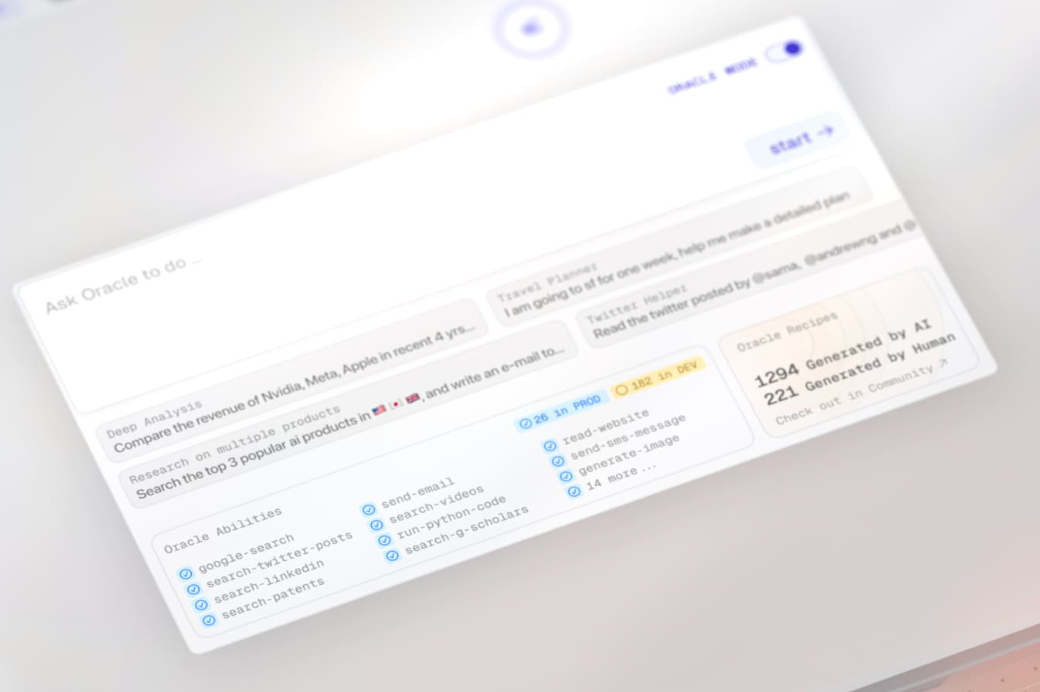
Tools supported by Oracle
- Memory 记忆和上下文管理
Oracle 是为复杂工作而生,因此对于步骤较多的工作,会产生大量的上下文,如果我们将所有上文内容交给 LLM,则将影响它的工作表现。
因此 Oracle 在任务分配、执行的过程中,会智能的选择性使用上文信息,比如当 Oracle 执行到第 10 步时,它的记忆管理器会判断以上哪些步骤的信息是有必要的,并将必要的信息放入当前步骤的上文。因此,你无需担心上文过长的问题。
- 自我迭代和更新 Recipe
在每一步执行完后,Oracle 都会根据每一步骤的执行结果,对整个 Recipe 进行必要的更新,比如当它没有搜到需要的信息,它会给接下来的步骤中加入更多的搜索,以便它可以顺利完成任务。
当 Oracle 询问是否满意结果时,如果用户表示不满意,它也将生成更多的步骤,尝试为用户提供想要的结果。
✳️无限调用工具
| 工具名称 | 工具作用 |
|---|---|
| analyze_website_traffic | 分析特定网站流量;获取网站指标;检查网站参与度 |
| ask_user_more | 请求用户输入更多信息 |
| deep_thinking | 对某个主题进行深入分析 |
| gen_webpage | 生成网页;创建网站;设计用户界面;搭建在线平台;开发 Web 应用;构建数字形象;打造互联网门户;生成基于 Web 的解决方案;制作 PPT 演示文稿;设计信息图表;生成图表和曲线;数据可视化;生成思维导图和流程图 |
| generate_image | 生成图像;绘制图片;文本生成图像;画一只可爱的猫 |
| generate_python | 帮助用户运行 Python 代码;代码解释器;进行复杂数学运算;进行数据可视化;运行 Python 代码 |
| online_search | 使用 Google 搜索实时信息 |
| read_website | 读取网站内容;爬取网站信息;获取在线文章 |
| search_google_scholar | 搜索学术论文;查找学术文章 |
| search_images | Google 图片搜索 |
| search_jobs | 搜索工作机会 |
| search_linkedin_company | 在 LinkedIn 上搜索公司 |
| search_linkedin_people | 在 LinkedIn 上搜索人员,查找 LinkedIn 个人资料 |
| search_patents | 搜索专利;查找专利信息;检索发明内容 |
| search_products | 搜索产品;查找可购买的商品;比价;获取购物信息 |
| search_reddit_posts | 搜索 Reddit 帖子 |
| search_stackexchange_question | 搜索 Stack Overflow 帖子 |
| search_twitter | 搜索推文;查找 Twitter 帖子 |
| search_videos | 搜索 YouTube 视频;视频搜索 |
| search_websites | 搜索网站;查找链接;Google 搜索 |
| search_xiaohongshu_notes | 搜索小红书笔记 |
| send_email | 发送电子邮件;通过邮件联系他人 |
| send_rapid_email | 发送邮件;快速邮件投递 |
| summarize_and_decide | 总结内容 |
| translate_text | 翻译用户提供的内容 |
✳️无限上下文输出
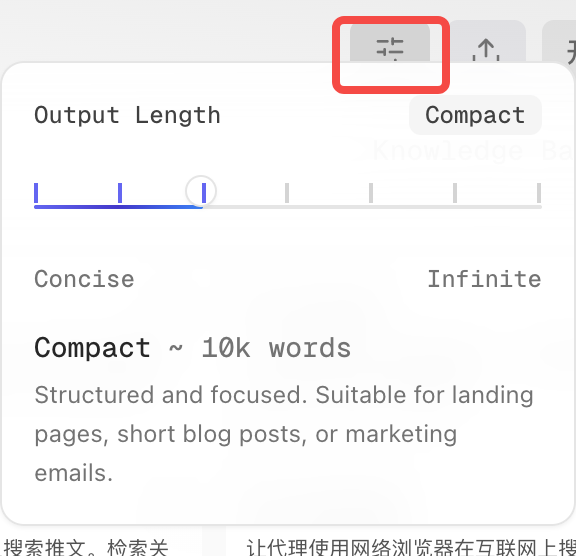
-
选择输出长度
-
简洁的
- **约1000字 **超轻量。非常适合标语、标题、推文或单句摘要。
-
简短的
- **约5000字 **简洁明了。非常适合产品描述、个人简介、社交帖子或常见问题解答。
-
紧凑的
- **约1万字 **结构清晰,重点突出。适用于落地页、短博客文章或营销邮件
-
详细的
- **约5 万字 **深入浅出,信息丰富。非常适合技术文章、提案或教程。
-
综合的
- **约25万字 **生成白皮书、产品手册、案例研究或多步骤交互。
-
详尽无遗的
- **约50万字 **广泛且系统性。适用于课程、设计系统、应用程序文档或大型知识库。
-
无限上下文输出
- **∞ 个单词 **世界构建规模。非常适合小说、平台蓝图、叙事游戏或政府级报告。
-
研究
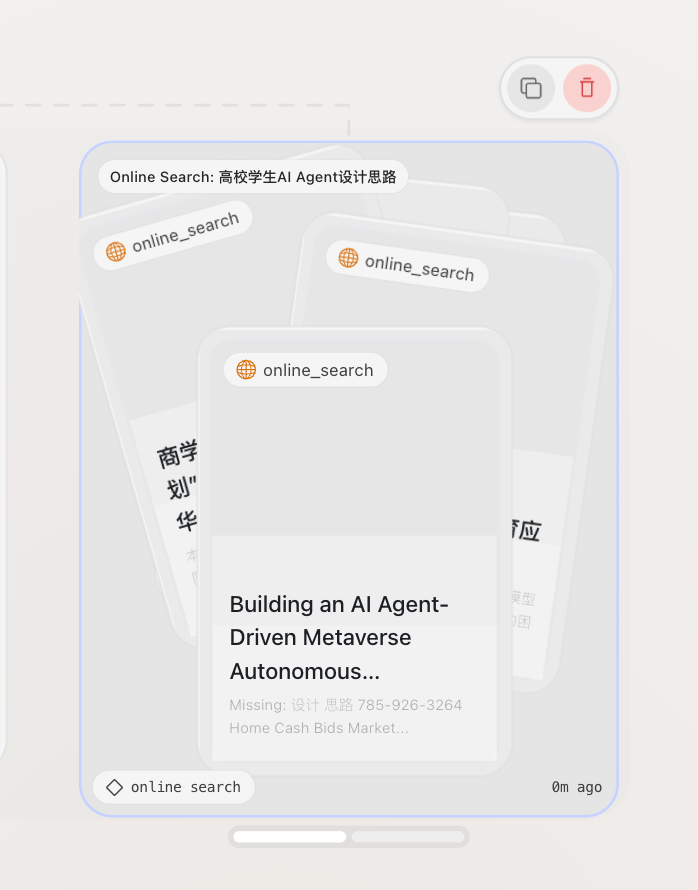
-
类似于gpt或者gemini的深度研究功能,能根据你的需求搜索资源并深度解析出调研报告;
-
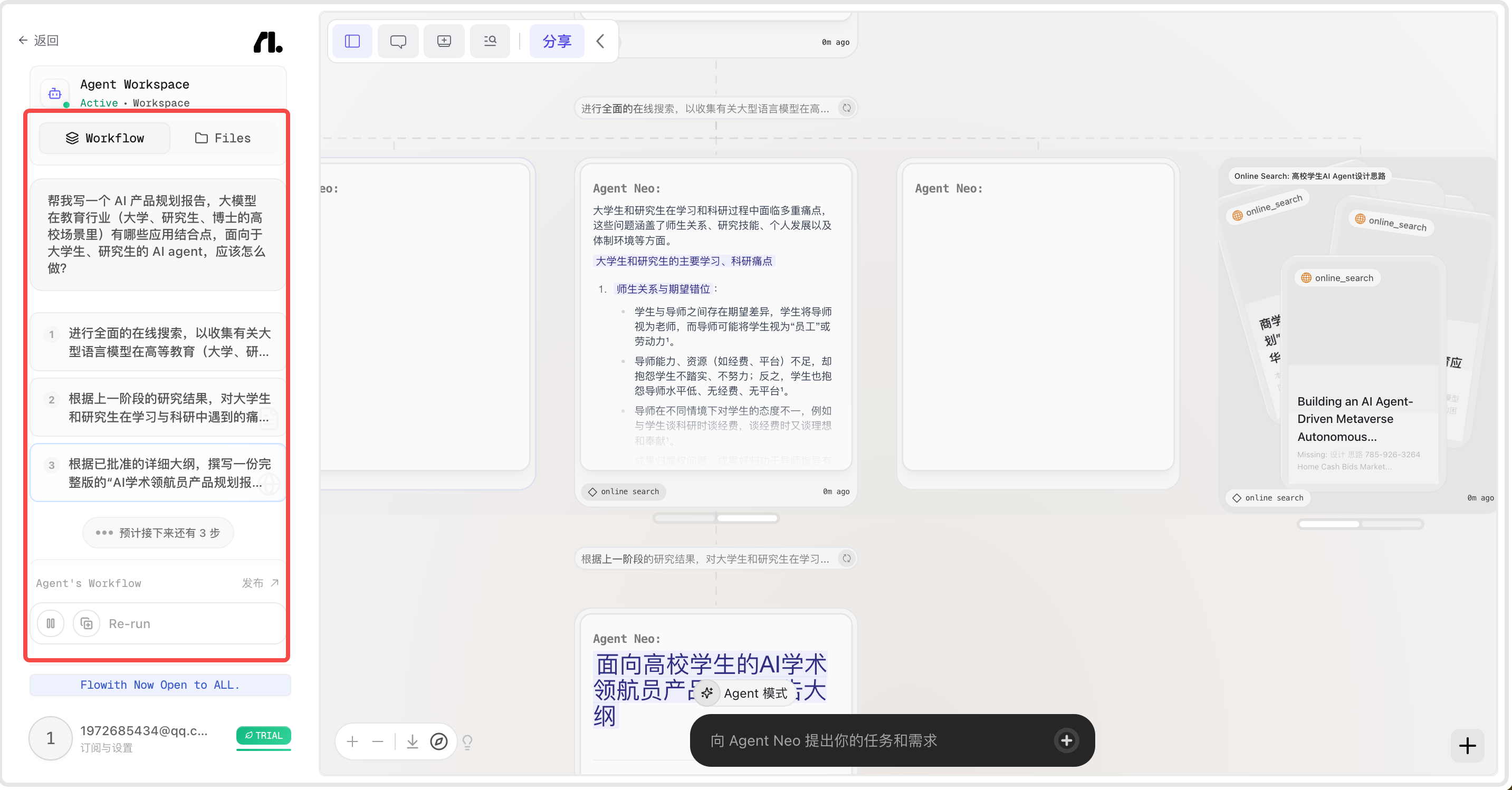
输入问题-做规划-左侧是行动的 workflow:
-
全网搜索:每个节点都可以重新运行,搜索出来的网页是堆叠的卡片
-
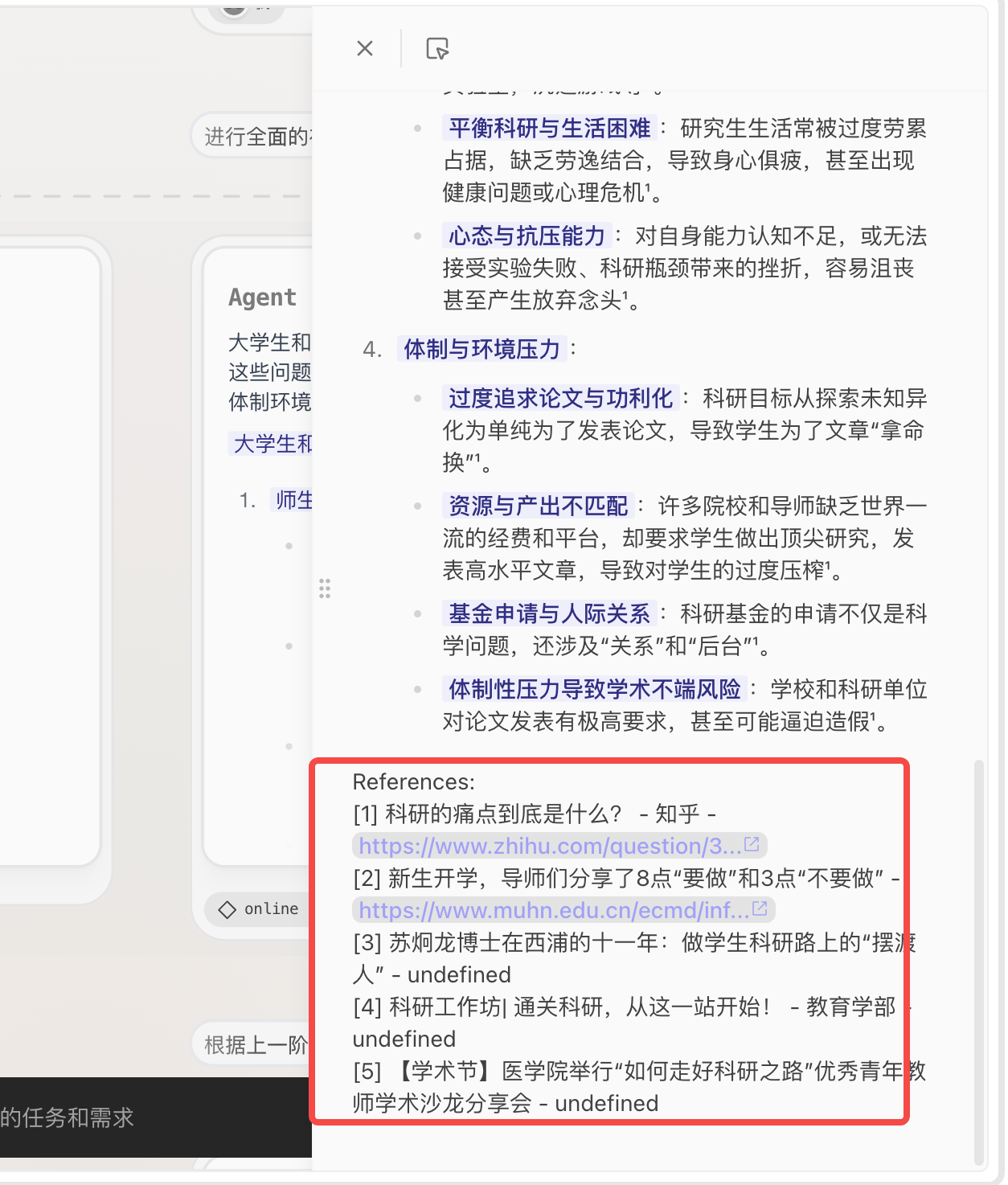
每个节点都有自己的参考链接
-
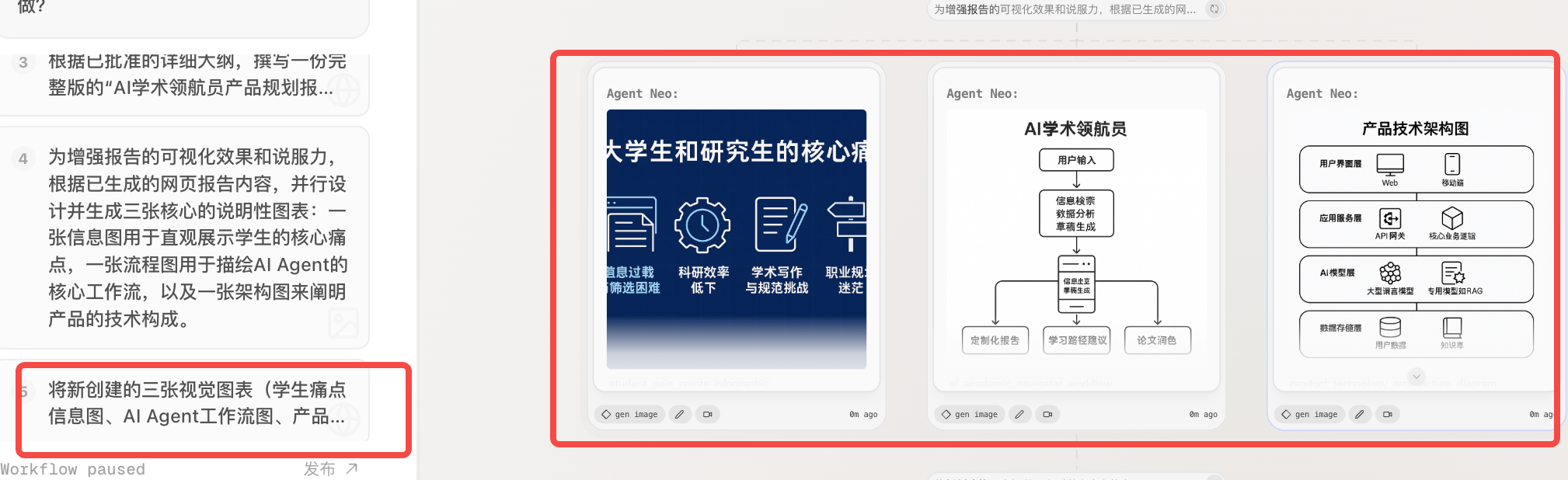
可以根据报告生成可视化的图表
-
-
最终生成的链接:flowith.io,但我觉得最终生成的文章的效果一般

创作 🤯🤯🤯
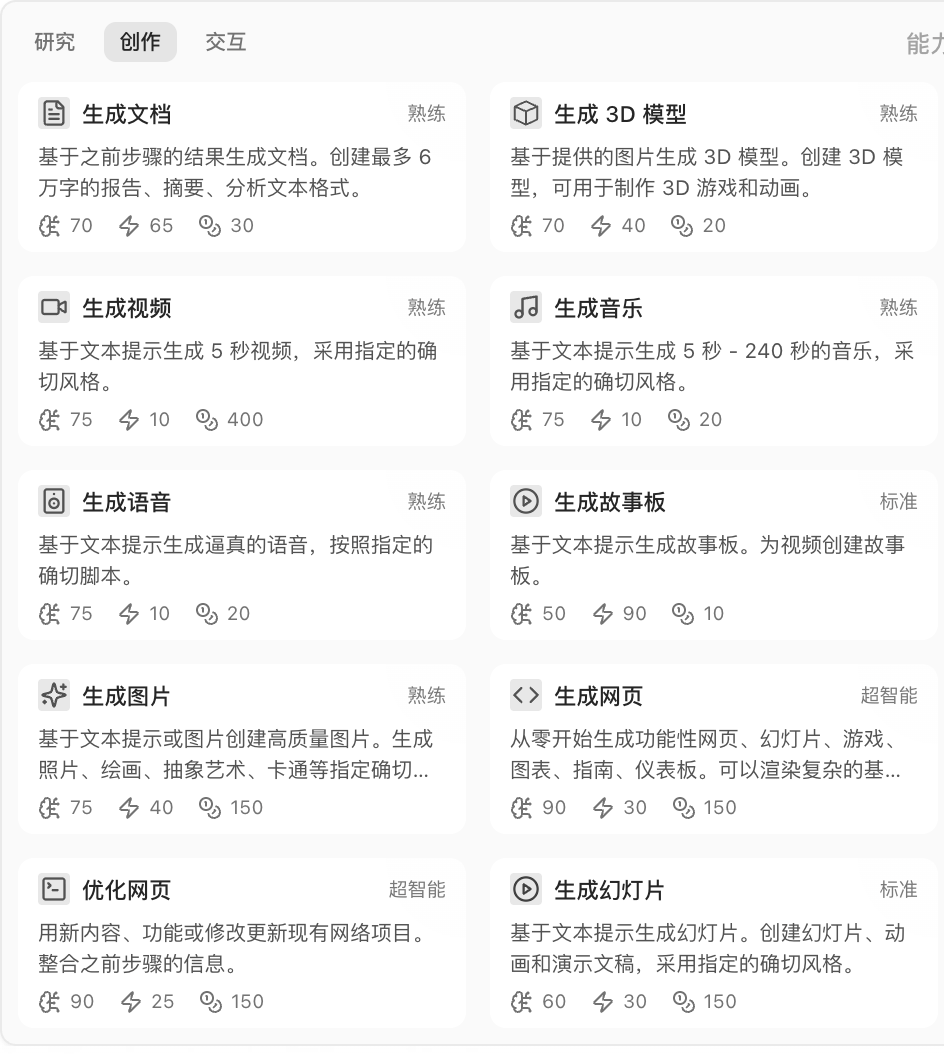
-
生成类的 AI
-
工作流非常细致
提示词:
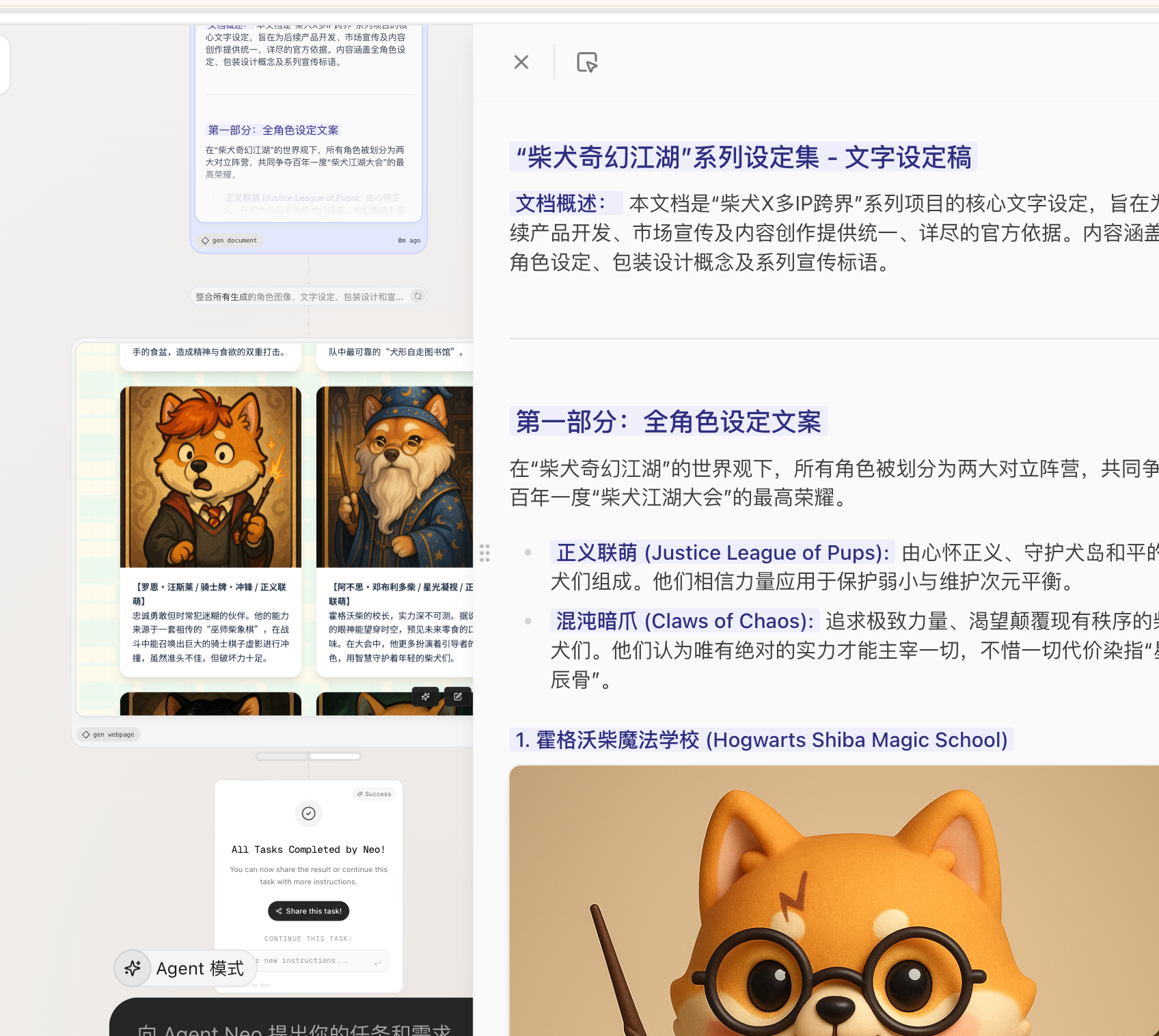
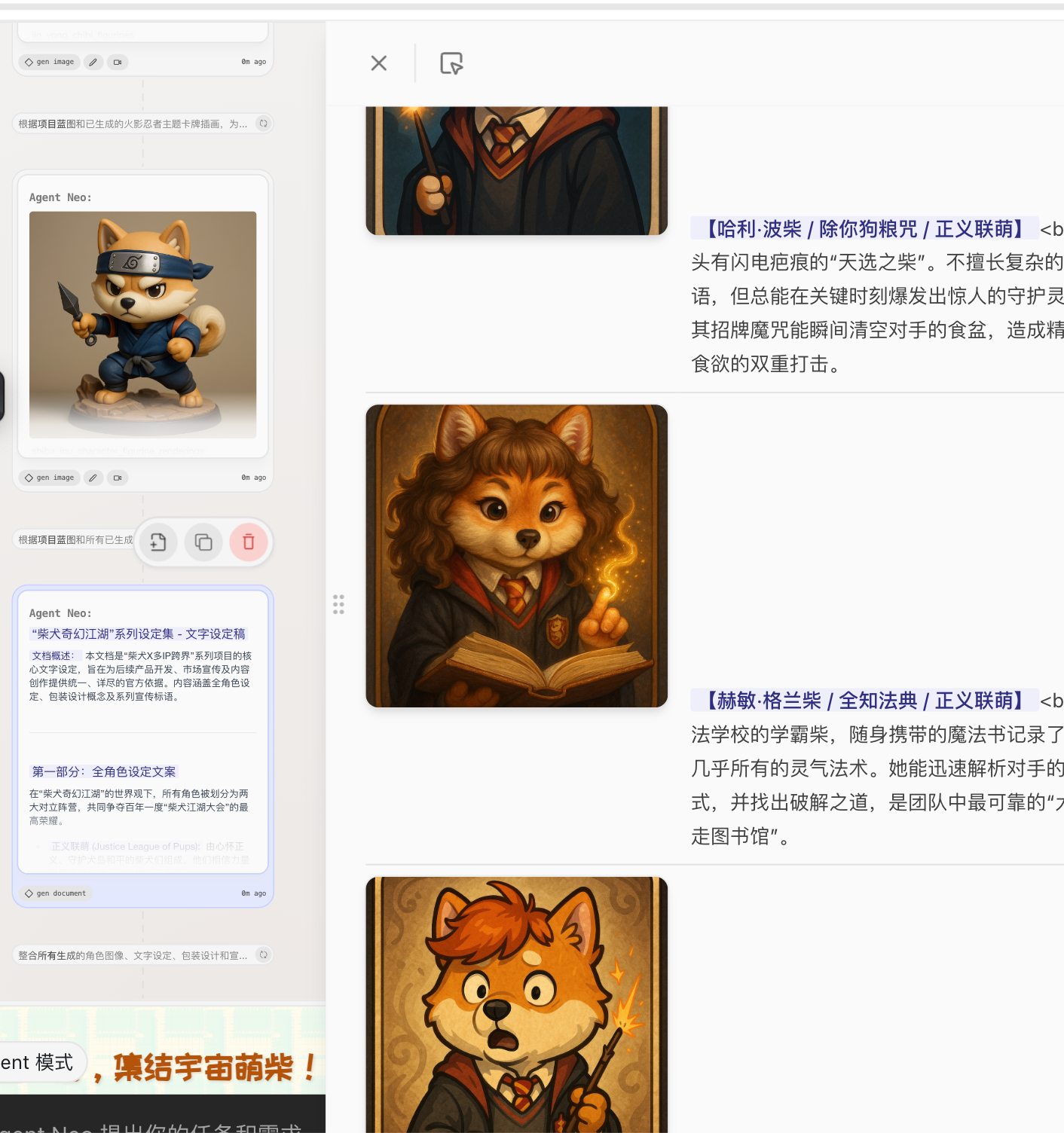
你是一名多模态AI设计助手,需要根据以下要求生成一套柴犬主题的卡牌+手办系列角色图集:
**任务描述:
**为“柴犬 X 多IP跨界”系列创造角色形象。该系列以柴犬角色为主角,融合多个经典IP元素,整体拥有统一的世界观和美术风格。输出包括角色图像和文字设定两部分。
具体要求: 1. **角色形象图生成:**绘制不少于 100 张角色图像。角色均为拟人化柴犬形象,分属不同经典IP主题。每个角色需绘制两种形态:
- **卡牌插画:**展现角色半身像或特写,突出其职业技能和IP特点,画面风格精致统一。
- **手办模型渲染:**展现角色全身立体造型,如3D手办,背景为简洁场景或底座。造型细节和配色需与卡牌插画一致。
提示:经典IP包括哈利·波特、漫威(复仇者联盟等英雄)、金庸武侠(射雕三部曲角色)、火影忍者等。请为每个IP衍生出多个柴犬角色(每个IP主题下角色形象风格应有所区分但整体系列视觉风格需统一)。
2. **统一世界观与风格:**设定一个统一的世界观背景(例如魔法学院、平行宇宙等),让来自不同IP主题的柴犬角色共存于此世界。美术上采用统一的主题风格,如 Q版奇幻风 或 国风武侠卡通风,保证所有图像在色调、线条、光影上风格一致,不出现不协调元素。
3. **角色设定文案:**为系列中每张卡牌撰写背景设定,包括:
- **角色名称:**体现IP元素和柴犬特征,如“柴犬巫师赫奇”等。
- **能力说明:******简述角色的职业技能、特殊能力,以及该能力与其IP背景的关联。
- 所属阵营:****划分阵营/派系,例如正义联盟、反派阵营、门派流派等,以丰富世界观的对立面。 文案要求言简意赅、有创意,贴合角色形象和IP特点。
4. 盲盒包装与宣传语:设计整套系列的盲盒手办包装概念,描述包装主视觉元素(包含柴犬和各IP元素的融合图案)以及配色风格。提出系列**************宣传标语**********,字数控制在一句话内,要求朗朗上口,突出柴犬IP跨界主题和收藏价值。 输出格式:
- 请按照 IP 分类组织输出内容,每个IP下列出该主题的角色图像和文字设定。先给出IP主题标题(例如:“哈利波特主题”),然后依次列出该主题下各角色的卡牌图与手办图,以及对应的角色名与设定说明。
- 图像部分:请直接呈现生成的卡牌插画和手办渲染图(确保图像清晰、美观、风格一致)。在文字中以适当方式标注图像(例如每张图像下附简短描述)。
- 文案部分:在每个角色的图像下方给出“角色名 / 能力 / 阵营:说明…”。所有角色信息尽量对齐格式,便于阅读比较。
- 包装与标语:在所有角色列举完毕后,新增小节描述盲盒包装设计,并以****加粗形式给出系列宣传标语。
请确保所有输出满足上述要求,图文对应且完整无遗漏。- 工作流非常细致,一共 12 步骤

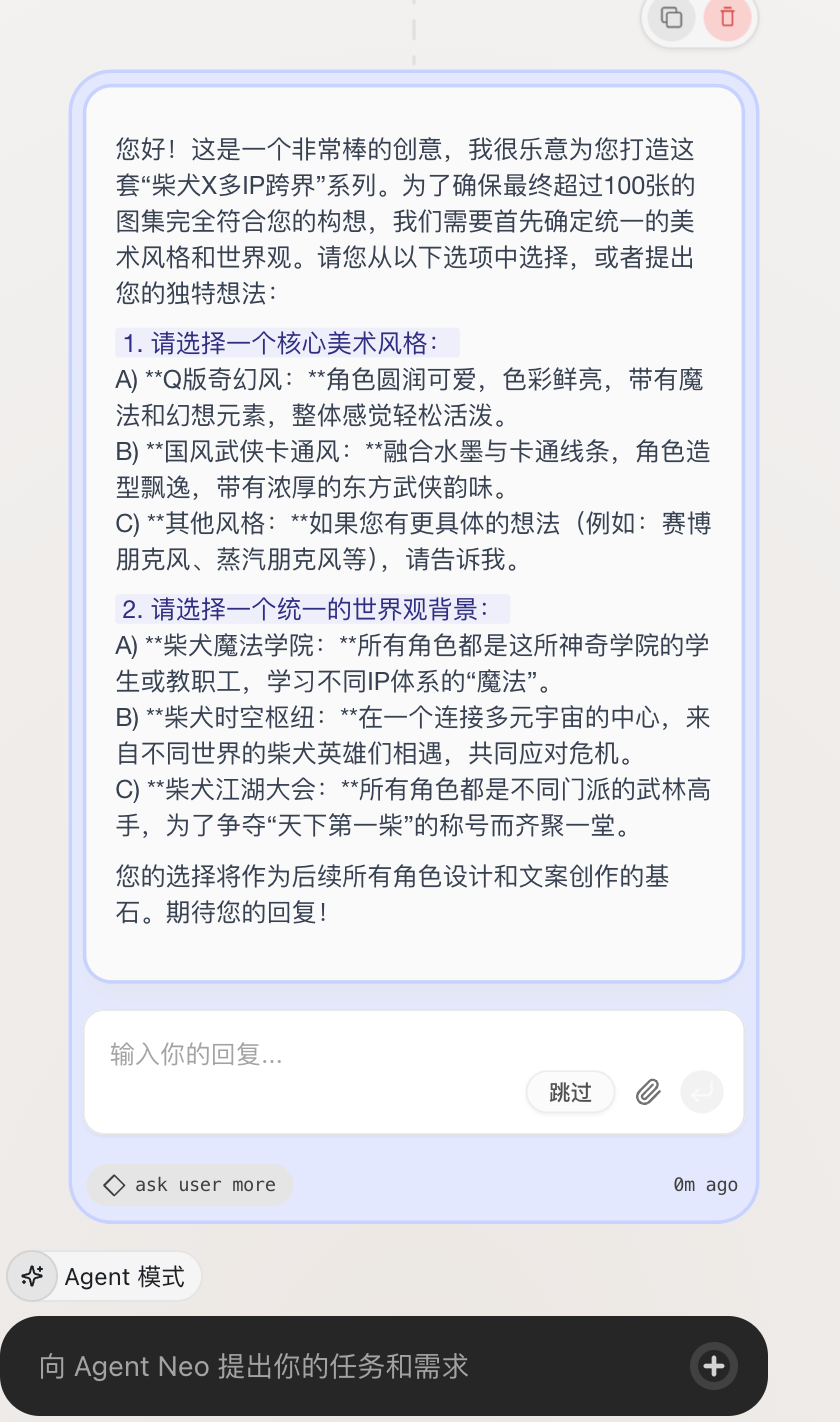
- 最终生成的效果:一次性跑出一整个系列的图片,而且质量非常高
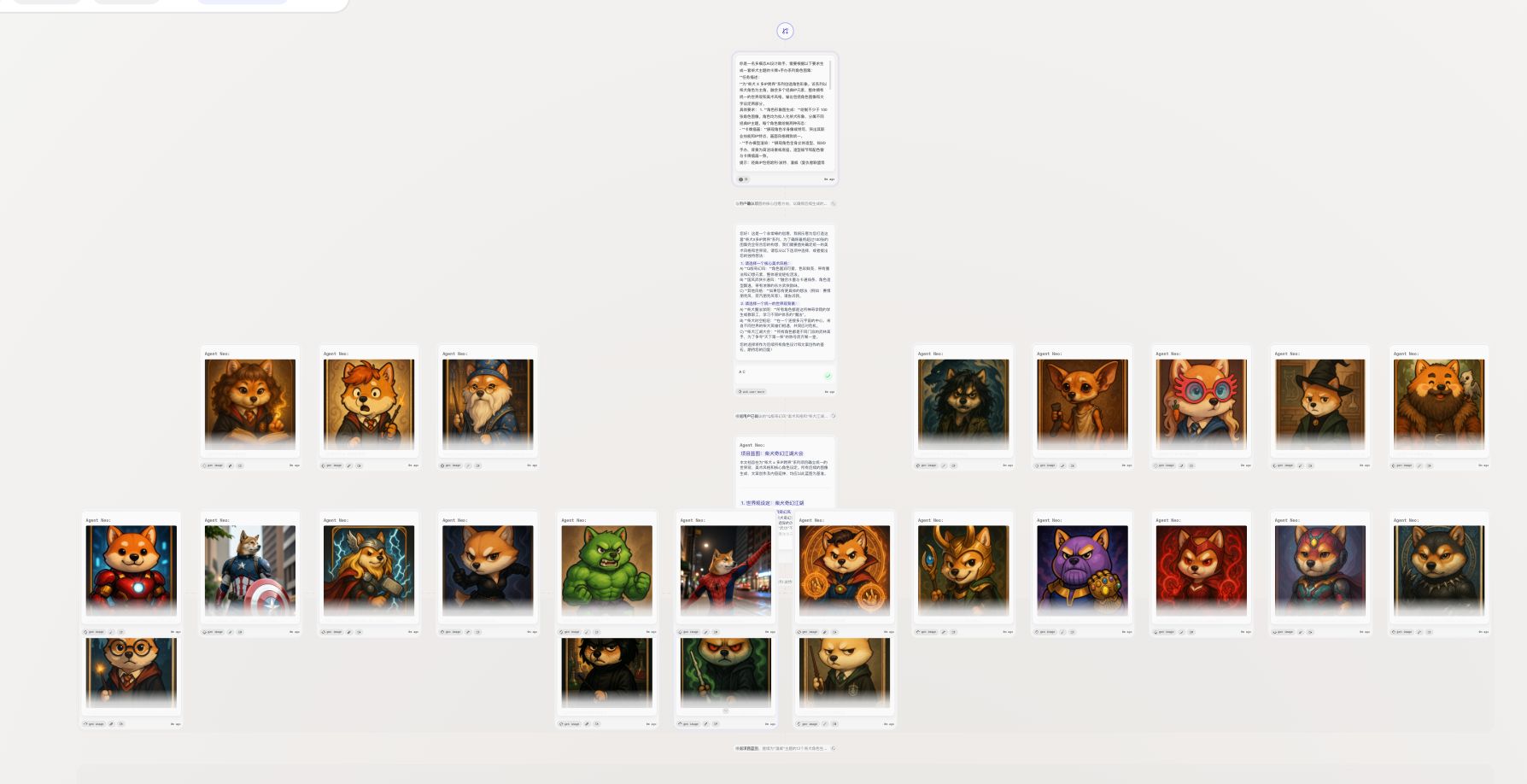
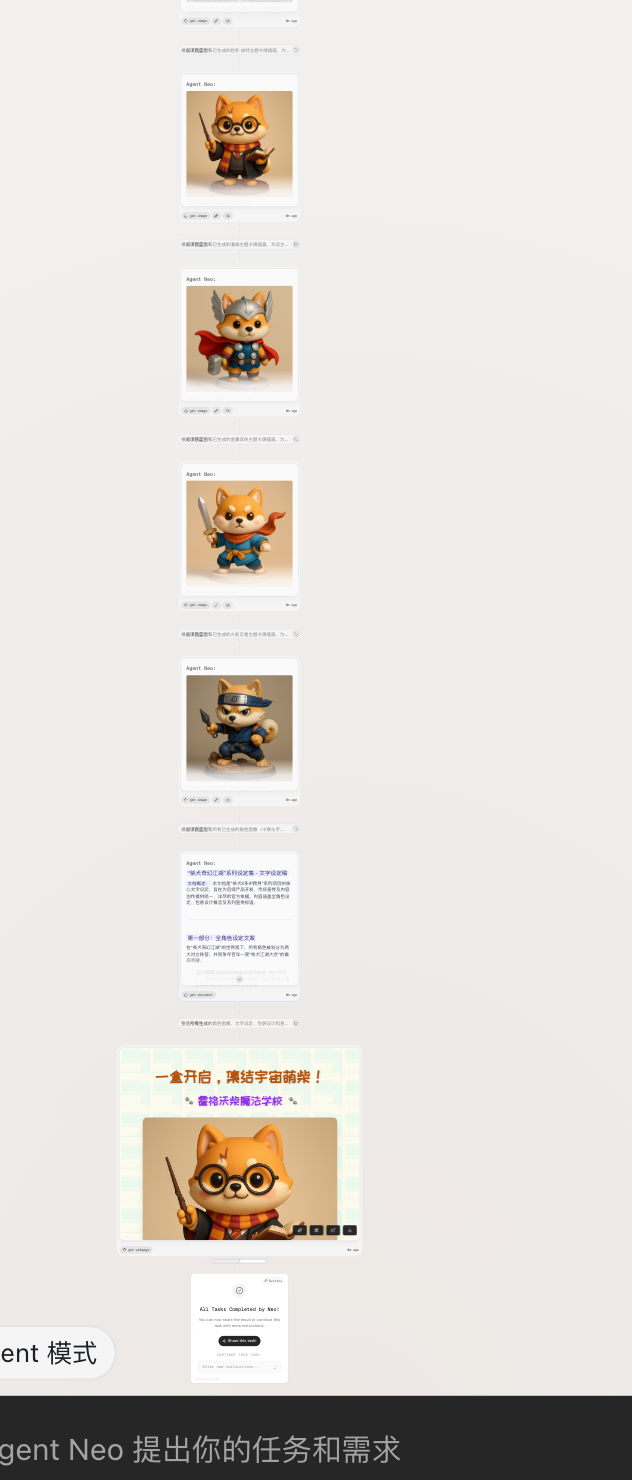
- 还能给出一整个世界观,对应关系,有点震惊我了🤯
-
最后生成的网页:https://flo\.host/A2f\-WFJ/
交互
收费方式