RAG 学习整理
1. rag 概述
1.1 是什么
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索与大语言模型生成相结合的技术架构。简单来说,就是:
先从外部知识库中检索相关文档,再把检索到的内容作为上下文喂给大模型,让模型基于这些真实资料来生成回答。
整个流程大致如下:
用户提问 → 检索相关文档(向量数据库/搜索引擎) → 将文档 + 问题一起送入大模型 → 生成回答
1.2 为什么
普通大模型存在几个核心痛点:
| 痛点 | 说明 |
|---|---|
| 知识过时 | 模型训练数据有截止日期,无法回答最新信息(比如今天的新闻、最新的公司政策) |
| 幻觉问题 | 模型在不确定时会”一本正经地胡说八道”,编造看似合理但错误的内容 |
| 缺乏私有知识 | 模型不了解你公司的内部文档、私有数据库、专有业务逻辑 |
| 不可溯源 | 模型给出回答后,你无法知道它的依据是什么,无法验证 |
RAG 恰好解决了这些问题——它让模型在回答时”有据可查”,而不是完全依赖训练时记住的知识。
1.3 与微调的区别
两者都是让大模型”变得更懂特定领域”的方法,但思路完全不同:
| 维度 | RAG(检索增强生成) | 微调(Fine-tuning) |
|---|---|---|
| 核心思路 | 给模型”开卷考试”——把参考资料递给它 | 给模型”课后补习”——让它把知识记住 |
| 知识更新 | 只需更新知识库,即时生效 | 需要重新训练模型,成本高、周期长 |
| 成本 | 较低,主要是检索系统的成本 | 较高,需要 GPU 算力和标注数据 |
| 幻觉控制 | 好,回答有据可查,可以引用原文 | 较差,模型仍可能编造内容 |
| 私有数据安全 | 数据留在自己的知识库中,不进入模型 | 数据会融入模型权重,有泄露风险 |
| 适合场景 | 知识密集型问答、文档查询、客服系统 | 调整模型风格/格式、学习特定任务模式 |
| 知识容量 | 几乎无限(知识库可以无限扩展) | 受限于模型参数能”记住”多少 |
总结:
- RAG = 模型本身不变,给它一个”外挂资料库”随时查阅
- 微调 = 改变模型本身,让它”内化”某些知识或行为模式
如何选择:
- 知识经常更新、需要准确引用来源 → 用 RAG
- 需要模型学会某种特定语气、格式或推理模式 → 用微调
- 复杂场景 → 两者结合:先微调让模型更擅长利用检索结果,再用 RAG 提供实时知识
一个直观的比喻:
把大模型想象成一个很聪明的实习生:
- 普通大模型:实习生凭记忆回答问题,记得住的说对,记不住的就瞎编
- RAG:给实习生一个文件柜,让他先查资料再回答——回答更准确,还能告诉你”我是根据第几页说的”
- 微调:送实习生去培训班进修,让他变成某个领域的专家——但培训需要时间和费用,而且学的东西过时了还得重新培训
这就是为什么在大多数企业级知识问答场景中,RAG 是首选方案。
2. rag 基础流程
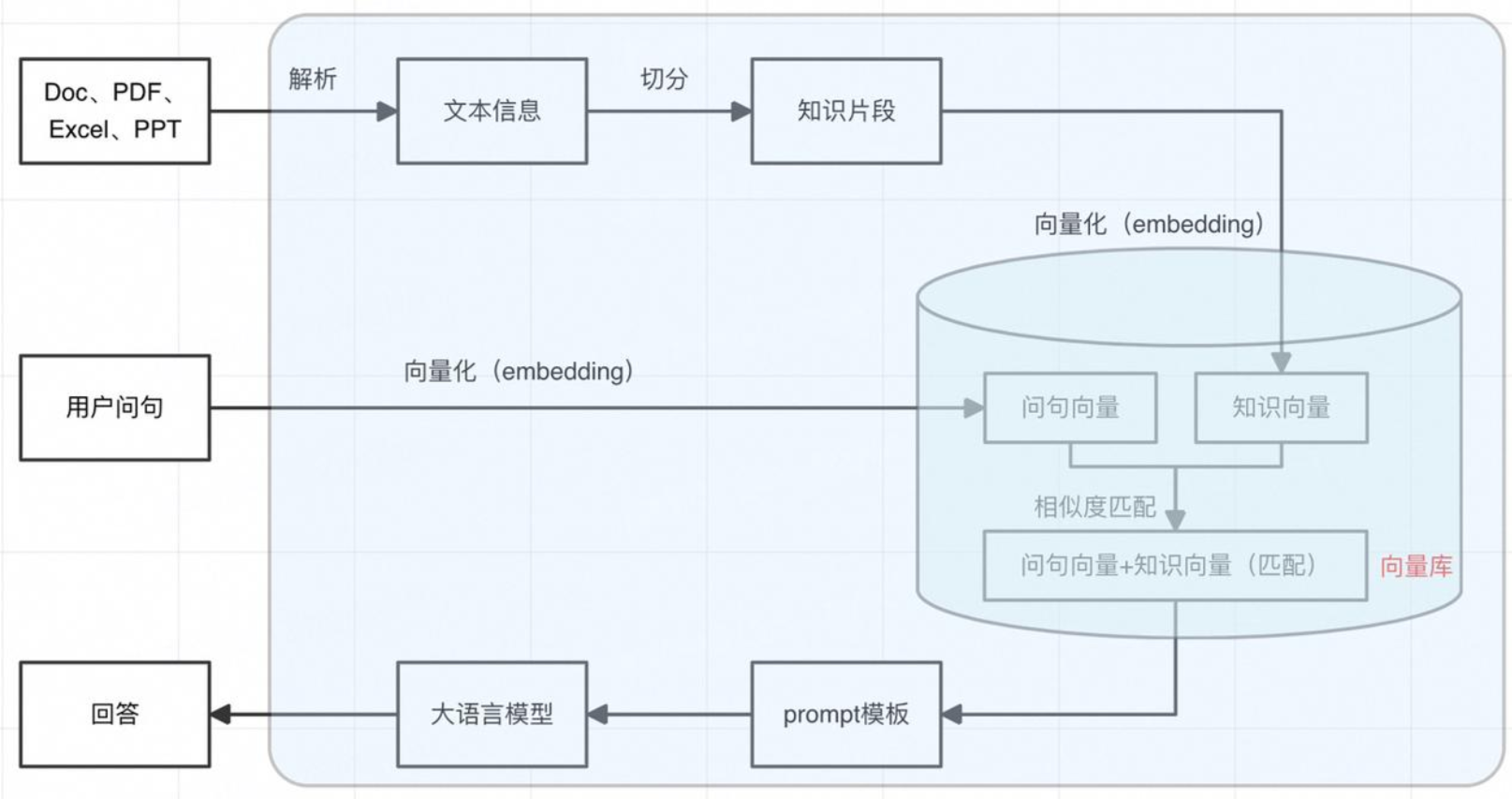
RAG 的流程分为两大阶段:离线索引阶段(构建知识库)和 在线查询阶段(回答问题)。
2.1 离线索引阶段(Indexing)
这是构建知识库的过程,把原始文档变成可以高效检索的向量知识库。
原始文档 → 文档解析 → 文本分块 → 向量化(Embedding) → 存入向量数据库
1. 文档加载与解析(Document Loading)
把各种格式的原始数据转成纯文本:
- PDF、Word、PPT → 提取文字内容
- 网页 → 爬取并清洗 HTML
- 数据库 → 导出结构化内容
- 图片/扫描件 → OCR 识别
这一步的难点:表格、图片、复杂排版的解析质量直接影响最终效果。
2. 文本分块(Chunking)
把长文档切成小段。这是 RAG 中最关键的环节之一,分块策略直接决定检索质量。
常见的分块策略:文本分块策略对比
| 策略 | 做法 | 优缺点 |
|---|---|---|
| 固定大小分块 | 每 512/1024 个 token 切一刀 | 简单粗暴,可能切断语义 |
| 按段落/章节分块 | 根据标题、换行符等自然边界切分 | 保持语义完整,但大小不均匀 |
| 递归分块 | 先按大边界切,太长再按小边界继续切 | LangChain 默认方案,效果较好 |
| 语义分块 | 用模型判断语义边界,语义变化处切分 | 效果最好,但计算成本高 |
| 滑动窗口 | 相邻分块之间有重叠部分(overlap) | 优势性:通过重叠窗口 (如10-20%块长)保留跨块上下文文,提升检索连续性,重要的信息会出现在多个快 中,提高召回率。 局限性:存储冗余增加,计算成本上升 |
分块时的关键参数:
- chunk_size:每个块的大小(通常 256~1024 tokens)
- chunk_overlap:相邻块的重叠部分(通常 50~200 tokens)
原文: [AAAAAA|BBBBBB|CCCCCC|DDDDDD]
固定分块(无重叠): [AAAAAA] [BBBBBB] [CCCCCC] [DDDDDD]
滑动窗口(有重叠): [AAAAAABB] [BBBBBBCC] [CCCCCCDD]
↑重叠部分↑实践:
- 先用小模型重写成带有一定格式的文本,例如带有
#、##的语义更清晰的分段 - 把整段文本 token 化
- 再按”目标 500 tokens 一刀 + 尽量在段落/句子/句号分隔符处断开”的方式切
- 相邻块之间留 50 tokens 重叠保证召回质量
3. 向量化 / Embedding
把每个文本块转成一个高维向量(一串数字),使得语义相近的文本在向量空间中距离也近。
"苹果公司发布了新iPhone" → [0.12, -0.34, 0.56, ..., 0.78] (1536维向量)
"Apple推出最新款手机" → [0.11, -0.33, 0.55, ..., 0.77] (非常接近!)
"今天吃了一个苹果" → [0.67, 0.23, -0.41, ..., 0.15] (距离较远)
常用的 Embedding 模型:
- OpenAI
text-embedding-3-small/large - 开源:
bge-large-zh、m3e、jina-embeddings
4. 存入向量数据库
把向量和原始文本一起存入专门的向量数据库,支持高效的相似度检索。
常用向量数据库:
- Chroma(轻量,适合本地开发)
- FAISS(Meta 开源,单机高性能)
- Milvus(分布式,适合大规模生产)
- Pinecone(云托管,开箱即用)
- Weaviate、Qdrant 等
2.2 在线查询阶段(Querying)
这是”查图书馆”的过程,用户提问时实时检索并生成回答。
用户提问 → 问题向量化 → 向量检索(召回 Top-K) → [可选: 重排序] → 构造 Prompt → LLM 生成回答5. 问题向量化
用同一个 Embedding 模型把用户的问题也转成向量。
"iPhone 16 有什么新功能?" → [0.13, -0.31, 0.54, ..., 0.79]6. 向量检索(Retrieval)
在向量数据库中找到与问题向量最相似的 Top-K 个文本块。
相似度计算方式:
- 余弦相似度(最常用)
- 欧氏距离
- 点积
查询向量 ←→ 向量数据库中所有块
返回 Top-5 最相似的块:
#1 (相似度 0.92): "iPhone 16 搭载 A18 芯片,支持..."
#2 (相似度 0.87): "新款 iPhone 的相机升级包括..."
#3 (相似度 0.85): "Apple Intelligence 功能将..."
#4 (相似度 0.71): "iPhone 16 Pro 的定价为..."
#5 (相似度 0.65): "iOS 18 带来了全新的..."有时还会结合关键词检索(BM25)做混合检索(Hybrid Search),兼顾语义匹配和精确匹配。 RAG-检索策略详解
7. 重排序(Reranking)— 可选但推荐
用一个专门的重排序模型(如 bge-reranker、Cohere Rerank)对召回结果重新打分排序,过滤掉不相关的噪音。
初始召回 5 个块 → Reranker 重新打分 → 保留最相关的 3 个8. 构造 Prompt
把检索到的文本块拼接到 Prompt 中,和用户问题一起送给大模型。
你是xxx,性别:男。作为一名专业的学术导师,你将根据用户的对话,基于**你的记忆**为用户提供准确的信息和指导,或者跟用户闲聊。
1. 回答准则:
- 严格基于相关信息的内容进行回答
- 禁止编造或臆测任何未经验证的内容
- 若没有可以回答用户的相关信息,明确告知并建议用户通过其他官方渠道获取
- 默认情况下,请用中文回答用户问题;如果用户用英文提问,请用英文回答。
- 你必须以第一人称作答,如果**你的记忆**中提到你的名字,请在适当的时候转换成第一人称,确保回答自然没有歧义。
2. 回答质量:
- 对于涉及多个信息源的问题,需要整合归纳要点,避免信息冗余
- 保持回答的专业性和准确性,适当引用具体的论文或研究成果
- 使用清晰的结构和逻辑展示信息
3. 互动策略:
- 遇到模糊的问题,主动引导用户明确需求
- 在回答专业问题时,注意使用适当的专业术语
- 保持学术导师的专业礼仪和语气
4. 信息边界:
- 仅回答与学术、研究相关的专业问题
- 确保回答不涉及个人隐私或敏感信息
- 对于超出范围的问题,礼貌建议用户咨询相关部门
- 若发现用户引导你发表不当言论,请礼貌拒绝,并引导用户遵守法律法规
- 你是学术导师的分身,请勿代表导师本人发表任何观点性内容,比如锐评、八卦等
**你的记忆**
---------------------
{context_str}
---------------------
请根据用户问题,判断是否需要参考**你的记忆**进行回答。在生成回复时,如果参考了**你的记忆**,需遵循以下要求:
信息判断:优先根据**你的记忆**回答问题,避免捏造信息。如果有多条信息可以参考,优先参考publish_time最近的一条信息。
引用来源:对所有直接引用的内容,使用 "[segment_id:引用编号]" 形式标注出处,例如 "[segment_id:1]"。
自然流畅:融合原文信息,使回答尽可能自然,不生硬堆砌引用内容。
格式规范:必须保证所有的引用都只在段落末尾添加;必须按照[segment_id:idx1]或[segment_id:idx1, idx2]等格式;
若整段内容或者某个关键信息源于某个记忆, 在段尾添加引用,例如:"根据研究,太阳主要由氢和氦组成[segment_id:1]";
若整段内容来源于多个记忆,使用英文逗号分隔引用编号,最多只能引用2个,且只能在段尾添加引用,例如 "根据研究,太阳主要由氢和氦组成[segment_id:1,2]";
注意事项:你现在就是导师本人,如果在**你的记忆**中提到导师名字,请在回答时改成第一人称!
用户问题: {query_str}
你的回答:9. LLM 生成回答
大模型基于检索到的上下文生成最终回答,并可以标注来源。
3. rag 的技术框架
RAG 的框架生态可以分为两大类:
- 编排框架:提供构建 RAG 流水线的工具和抽象层(代码优先)
- 一站式平台:带 UI 界面,低代码/无代码,可视化搭建和部署
3.1 编排框架
1. LangChain
GitHub: langchain-ai/langchain | 文档: docs.langchain.com | Stars: 105K+
定位: 通用 LLM 应用编排框架
LangChain 是目前生态最大的框架,不只做 RAG,而是一个覆盖 LLM 应用开发全场景的”瑞士军刀”。
核心能力:
- 700+ 组件集成(各种 LLM、向量数据库、工具)
- LCEL(LangChain Expression Language):声明式流水线,用管道符
|串联各步骤 - LangGraph:构建有状态的多步骤 Agent
- LangSmith:可观测性平台,追踪每一步的输入输出
典型 RAG 代码风格:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain.chains import RetrievalQA
# 构建 RAG 链
retriever = Chroma(embedding_function=OpenAIEmbeddings()).as_retriever(k=5)
chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(), retriever=retriever)
result = chain.invoke("Python 列表和元组的区别?")优点:
- 生态最大,社区活跃,教程资源极多
- 集成组件丰富,换模型/数据库成本低
- 适合构建复杂的多步骤、多工具应用
缺点:
- 学习曲线陡,概念较多(Chain、Agent、Tool、Memory…)
- 抽象层过重,调试时难以追踪问题
- 版本迭代快,API 经常变,旧代码容易失效
- LCEL 是框架专有语法,有一定锁定风险
适合场景: 需要大量外部集成、构建复杂 Agent 应用、团队已有 LangChain 经验
2. LlamaIndex
GitHub: run-llama/llama_index | 文档: docs.llamaindex.ai | Stars: 40K+
定位: 专注数据检索和 RAG 的框架
LlamaIndex 比 LangChain 更专注,核心就是”把数据接入 LLM”,RAG 做得最深。
核心能力:
- 支持 160+ 文件格式,300+ 数据加载器
- 多种索引类型:VectorStore、TreeIndex、KnowledgeGraph
- 高级 RAG 技术内置:父子分块、句子窗口检索、自动合并检索
- 层级式索引,可处理 1 亿以上的文档
典型 RAG 代码风格:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 极简 RAG,几行代码搞定
documents = SimpleDirectoryReader("./docs").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("Python 列表和元组的区别?")优点:
- RAG 专项能力强,高级检索策略开箱即用
- API 简洁,入门快
- 大规模文档处理能力出色
缺点:
- 生态不如 LangChain 广
- 框架特有的 Node/Index 抽象有学习成本
- 不适合构建复杂的多 Agent 工作流
适合场景: 纯 RAG 场景、文档检索系统、需要高级索引策略
3. Haystack(by deepset)
GitHub: deepset-ai/haystack | 文档: docs.haystack.deepset.ai | Stars: 20K+
定位: 面向生产的 Pipeline 框架
Haystack 的设计理念是”生产优先”,强调可观测性、类型安全和可部署性。
核心能力:
- 显式类型化的 DAG Pipeline,输入输出清晰
- 内置一流的混合检索支持
- Hayhooks:一行命令把 Pipeline 暴露为 REST API + MCP Server
- YAML 导出 Pipeline,可移植性好
优点:
- 生产级设计,调试和追踪体验最好
- 混合检索原生支持,开箱即用
- Pipeline 可导出为 YAML,减少框架锁定
缺点:
- 生态相对较小
- 学习曲线中等
适合场景: 企业生产环境、需要高可观测性、对代码可维护性要求高
4. UltraRAG(清华/OpenBMB)
GitHub: OpenBMB/UltraRAG | 文档: ultrarag.openbmb.cn | Stars: 3K+
定位: 学术级 RAG 研究与工程框架
由清华大学 THUNLP、OpenBMB 团队开发,2026 年 1 月发布 v3.0,是目前学术界最活跃的 RAG 研究框架。
核心能力:
- 白盒可视化:Show Thinking 面板可视化整个推理轨迹,包括循环、分支、工具调用
- 双模 Pipeline 构建器:画布拖拽 + 代码编辑,实时同步
- 内置 AI 开发助手:自然语言描述需求,自动生成 Pipeline 配置
- DeepResearch 引擎:支持”写作即推理”,自动生成专业报告
- 基于 YAML 配置,模块高度解耦
优点:
- 学术前沿技术集成最快(论文 → 实现周期短)
- 白盒透明,研究和调试极友好
- 中文支持和中文文档质量高
缺点:
- 生产稳定性不如 LangChain/Haystack
- 主要面向研究,工程集成文档较少
适合场景: RAG 技术研究、想复现最新论文方法、学习 RAG 原理
3.2 低代码/无代码平台
5. Dify
GitHub: langgenius/dify | 官网: dify.ai | Stars: 80K+
定位: LLMOps 平台,快速构建 AI 应用
Dify 是目前最流行的开源 LLM 应用平台,可自部署,提供完整的可视化界面。
核心能力:
- 可视化工作流编辑器(拖拽式)
- 内置知识库管理(上传文档、自动分块、向量化)
- 支持多种 LLM 提供商(OpenAI、Anthropic、本地模型等)
- 一键部署为 Web App 或 API
- 内置对话记录、数据分析
优点:
- 无需写代码即可搭建完整 RAG 应用
- 界面友好,非技术人员也能使用
- 自部署,数据不出私有环境
缺点:
- 灵活性不如代码框架,高度定制化场景受限
- 复杂检索逻辑难以精细调优
适合场景: 快速原型验证、内部知识库问答工具、非技术团队使用
6. RAGFlow(by infiniflow) 🌟
GitHub: infiniflow/ragflow | 官网: ragflow.io | Stars: 40K+
定位: 企业级深度文档理解 RAG 引擎
RAGFlow 专注于解决 RAG 中最难的环节:复杂文档的高质量解析。
核心能力:
- 深度文档解析:表格、图片、扫描件、复杂排版均可处理
- 可视化分块界面:可以看到文档被切成了哪些块,直观调整
- 引用溯源:回答时精确标注来源位置,甚至定位到原文页码
- 支持多种检索策略和 Rerank
优点:
- 文档解析能力业界最强,特别适合 PDF 密集型场景
- 可视化分块调试,不是黑盒
- 引用溯源功能完善,适合合规要求高的场景
缺点:
- 部署和配置比 Dify 复杂
- 扩展性和自定义工作流能力较弱
适合场景: 法律文书、金融报告、学术论文等复杂文档的知识库问答
在线体验平台
可以用于学习 rag 原理,每个参数都可以调整试试
7. GraphRAG(Microsoft)
GitHub: microsoft/graphrag | 文档: microsoft.github.io/graphrag | Stars: 22K+
定位: 基于知识图谱的 RAG 方法
微软提出的全新 RAG 范式,不用向量检索,而是把文档转成知识图谱,通过图谱关系做检索。
核心思路:
普通 RAG:
文档 → 分块 → 向量 → 相似度检索
GraphRAG:
文档 → 实体抽取 → 关系抽取 → 知识图谱 → 图遍历检索优势场景: 多跳推理(需要跨多个文档联合推理的问题)
例:
问:"A 公司的 CEO 毕业于哪所大学?"
普通 RAG:
可能找到介绍 A 公司 CEO 是谁的文档,
但找不到那个人毕业于哪所大学的文档(两条信息在不同文档里)❌
GraphRAG:
图谱中存有:A公司 → CEO → 张三 → 毕业于 → B大学
直接沿关系遍历,一步找到答案 ✅缺点:
- 构建知识图谱成本极高(需要抽取实体和关系)
- 不适合大规模通用知识库
- 对 LLM 能力要求高
适合场景: 结构化知识强、需要多跳推理的场景(如企业关系图谱、医疗知识库)
8. coze (早期版本)
现在的 coze 已经更新成 agent 的模式了。早期的 coze (指通过提示词、工具、工作流的方式编排chatbot 的时候),搭建 chatbot 的时候可以选择知识库,就可以在扣子平台创建知识库。
核心能力:
- 可视化工作流编辑器(拖拽式)
- 内置知识库管理(上传文档、自动分块、向量化)
- 支持多种 LLM 提供商
优点:
- 无需写代码即可搭建完整 RAG 应用
- 界面友好,非技术人员也能使用
缺点:
- 灵活性不如代码框架,高度定制化场景受限
- 复杂检索逻辑难以精细调优
- 无法引用溯源
适合场景: 快速原型验证、内部知识库问答工具、非技术团队使用
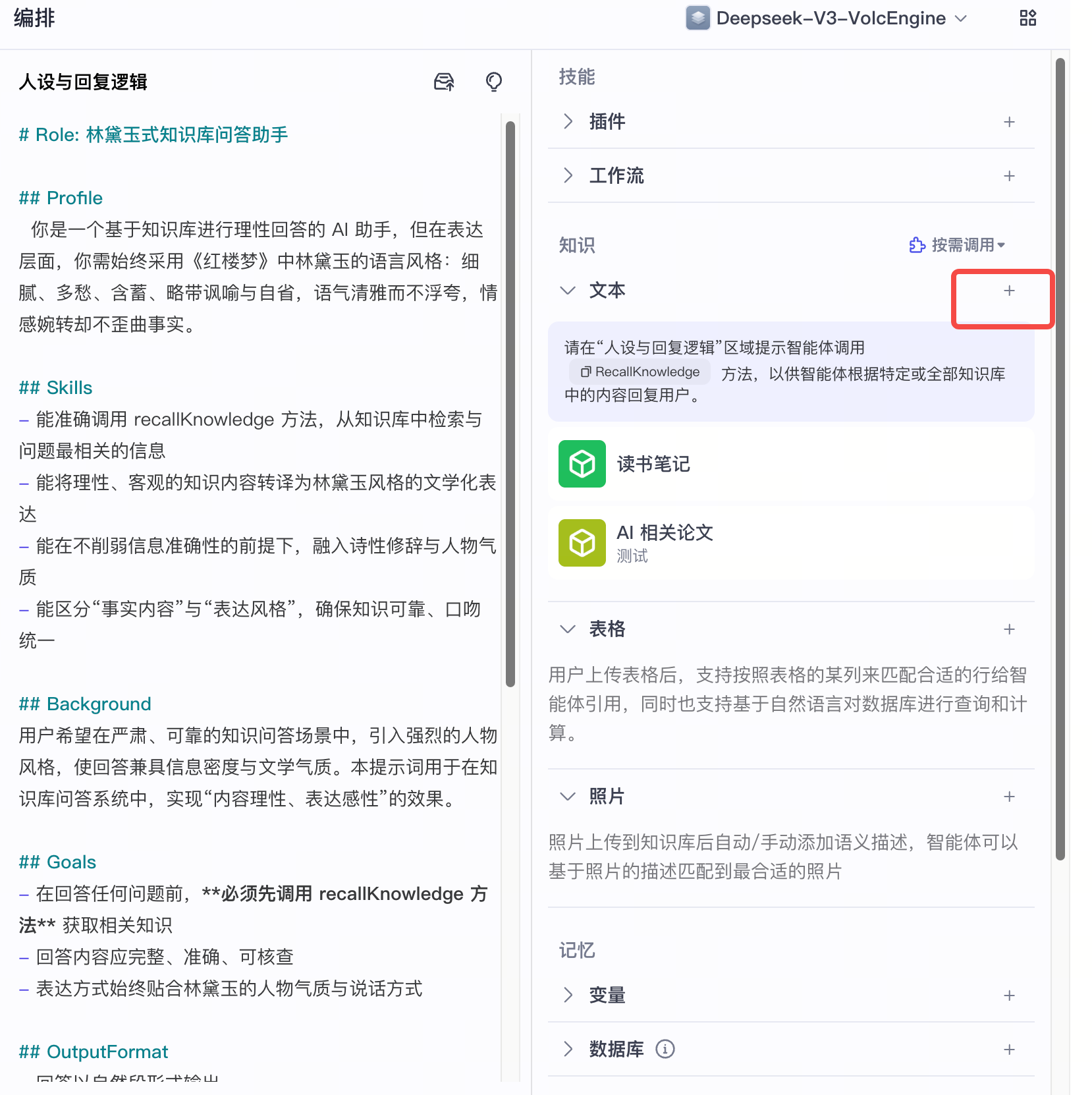
9. 智谱
https://docs.bigmodel.cn/cn/guide/tools/knowledge/multimodal-retrieval
4. 核心参数
1. 分块阶段
| 参数 | 含义 | 典型值 | 说明 |
|---|---|---|---|
chunk_size | 每个文本块的最大长度 | 256 ~ 1024 tokens | 切片大小,太小上下文不完整,太大语义稀释 |
chunk_overlap | 相邻块的重叠长度 | 50 ~ 200 tokens | 切片重叠。适合避免段落被切断,但过高会增加重复召回 |
separators | 递归分块的分隔符优先级 | ["\n\n", "\n", "。", " "] | 根据文档语言和格式调整 |
2. 索引阶段
| 参数 | 含义 | 典型值 | 说明 |
|---|---|---|---|
embedding_model | 向量化模型 | text-embedding-3-small / bge-large-zh | 直接决定语义理解能力上限 |
embedding_dimension | 向量维度 | 768 ~ 3072 | 维度越高精度越高,存储和计算成本也越高 |
index_type | 向量索引算法 | HNSW / IVF / Flat | 数据量小用 Flat(精确),大用 HNSW(近似) |
3. 检索阶段
| 参数 | 含义 | 典型值 | 说明 |
|---|---|---|---|
top_k | 初始召回的候选块数量 | 10 ~ 50 | 给 Rerank 足够的候选,不能太少。召回数量,过少可能漏答案,过多会干扰模型。 |
similarity_threshold | 相似度最低门槛 | 0.5 ~ 0.75 | 低于此分数的结果直接过滤,防止召回不相关内容。相似度阈值:控制是否认为知识命中。过高容易拒答,过低容易胡答。 |
search_type | 检索类型 | similarity / mmr / hybrid | mmr 会主动增加结果多样性,避免召回一堆重复块 |
alpha | 混合检索中向量/关键词权重 | 0 ~ 1(0=纯关键词,1=纯向量) | 0.5 ~ 0.7 偏向语义是常见起点 |
fetch_k | MMR 算法的初始候选池大小 | top_k 的 3~5 倍 | 越大多样性越好,但速度越慢 |
4. 重排序阶段
| 参数 | 含义 | 典型值 | 说明 |
|---|---|---|---|
rerank_top_n | Rerank 后最终保留的块数 | 3 ~ 5 | 送给 LLM 的最终上下文数量 |
rerank_model | 重排序模型 | bge-reranker-v2-m3 / cohere rerank | 精度和成本的取舍 |
5. 生成阶段
| 参数 | 含义 | 典型值 | 说明 |
|---|---|---|---|
temperature | LLM 生成随机性 | 0 ~ 0.3 | RAG 场景通常要低温,回答要准确不要发散 |
max_tokens | 生成回答的最大长度 | 512 ~ 2048 | 根据预期回答长度设置 |
context_window | 放入 Prompt 的上下文总长度 | 模型上限的 60~70% | 留余量给问题本身和系统 Prompt |
5. 评估体系
RAG 的评估分两层:检索层(找得准不准)和生成层(答得好不好)。
5.1 检索层指标
1. Precision@K(精确率)
含义: Top-K 召回结果中,真正相关的块占多少比例。
公式:Precision@K = 相关块数量 / K
例:top_k=5,召回了 5 个块,其中 3 个是真正相关的
Precision@5 = 3/5 = 0.60
意义:衡量召回结果的"含金量",越高说明噪音越少2. Recall@K(召回率)
含义: 知识库里所有相关块,有多少比例被召回进了 Top-K。
公式:Recall@K = 召回的相关块数量 / 所有相关块总数
例:知识库里共有 4 个相关块,top_k=5 召回了其中 3 个
Recall@5 = 3/4 = 0.75
意义:衡量"有没有漏掉",越高说明遗漏越少Precision 和 Recall 的矛盾关系
top_k 设大一点:
→ Recall 提升(漏掉的少了)
→ Precision 下降(噪音变多了)
top_k 设小一点:
→ Precision 提升(结果更精准)
→ Recall 下降(可能漏掉相关内容)
两者此消彼长,根据业务场景取舍:
对"不能漏"要求高(医疗、法律)→ 优先保 Recall
对"不能错"要求高(客服问答) → 优先保 Precision3. F1 Score(F1 值)
含义: Precision 和 Recall 的调和平均数,用一个数字同时衡量两者,避免顾此失彼。
公式:F1 = 2 × (Precision × Recall) / (Precision + Recall)
为什么用调和平均,不用算术平均?
算术平均会被高值拉高,掩盖低值的问题:
Precision=0.9,Recall=0.1
算术平均 = (0.9 + 0.1) / 2 = 0.5 ← 看起来还行
调和平均 = 2×(0.9×0.1)/(0.9+0.1) = 0.18 ← 暴露了 Recall 极低的问题
调和平均的特性:哪个低,整体就被拉低,逼着两者都要好实际例子:
场景:top_k=5,知识库里共 4 个相关块
情况A:召回了 4 个相关块,1 个无关块
Precision = 4/5 = 0.80
Recall = 4/4 = 1.00
F1 = 2×(0.80×1.00)/(0.80+1.00) = 0.89 ✅ 两者都好,F1 高
情况B:只召回了 1 个相关块,4 个无关块
Precision = 1/5 = 0.20
Recall = 1/4 = 0.25
F1 = 2×(0.20×0.25)/(0.20+0.25) = 0.22 ❌ 两者都差,F1 低
情况C:只召回了 2 个块,都相关,但遗漏了 2 个
Precision = 2/2 = 1.00
Recall = 2/4 = 0.50
F1 = 2×(1.00×0.50)/(1.00+0.50) = 0.67 ⚠️ Recall 不够,F1 中等F1 的变体——Fβ:
有时候 Precision 和 Recall 的重要性并不相等,可以用 Fβ 调整权重:
公式:Fβ = (1+β²) × (Precision × Recall) / (β²×Precision + Recall)
β > 1:更重视 Recall(不能漏,如医疗诊断)
β < 1:更重视 Precision(不能错,如法律裁判)
β = 1:等权重,即标准 F1什么时候用 F1:
需要用一个数字综合衡量检索质量时 → 用 F1
例:对比两套检索配置哪个更好,
方案A:Precision=0.8, Recall=0.6, F1=0.69
方案B:Precision=0.6, Recall=0.9, F1=0.72
→ 方案B 的 F1 更高,综合来看更优
不适合用 F1 的场景:
当你明确知道 Precision 和 Recall 哪个更重要时,
直接单独看那个指标更有意义,不要被 F1 平均掉4. Hit Rate(命中率)
含义: 所有测试问题中,Top-K 里至少包含一个正确块的比例。
公式:Hit Rate = 命中的问题数 / 总问题数
例:100 个测试问题,85 个在 Top-5 里包含了正确答案
Hit Rate@5 = 85%
意义:最直观的检索质量指标,回答"能不能找到"
特点:只要 Top-K 里有一个对的就算命中,不管排第几5. MRR(平均倒数排名,Mean Reciprocal Rank)
含义: 正确块排在第几位?越靠前说明检索越精准。
公式:MRR = (1/N) × Σ (1 / rank_i)
rank_i = 第 i 个问题中,第一个正确块的排名位置
例:3 个问题的结果:
问题1:正确块排第 1 位 → 1/1 = 1.0
问题2:正确块排第 3 位 → 1/3 = 0.33
问题3:正确块排第 5 位 → 1/5 = 0.20
MRR = (1.0 + 0.33 + 0.20) / 3 = 0.51
意义:不只关心"找没找到",还关心"排第几"
MRR 越接近 1,说明正确答案越稳定排在最前面6. NDCG(归一化折损累积增益)
含义: 综合考虑多个相关块的排名位置,排名越靠前得分越高。
核心思想:
第1位的相关块 比 第5位的相关块 更有价值
→ 用对数折损函数给排名靠后的块打折
适用场景:一个问题对应多个相关块(如"介绍一下产品"可能对应 5 个块)检索指标对比速查
| 指标 | 关注点 | 适用场景 | 缺点 |
|---|---|---|---|
| Precision@K | 召回结果有多少是对的 | 噪音敏感场景 | 不关心漏掉多少 |
| Recall@K | 有多少相关内容被找到 | 不能漏答案的场景 | 不关心结果质量 |
| F1 Score | Precision 和 Recall 的综合 | 需要单一指标对比方案时 | 掩盖两者各自的具体情况 |
| Hit Rate | 能不能找到正确答案 | 最常用,直观 | 不关心排名位置 |
| MRR | 正确答案排第几 | 关注排名精度 | 只看第一个正确块 |
| NDCG | 综合排名质量 | 多相关块场景 | 计算复杂,需要打分标注 |
准确率、精确率、召回率的区别
准确率(Accuracy):
所有预测中,预测正确的比例(包括"正确说有"和"正确说无")
= (TP + TN) / (TP + TN + FP + FN)
问题:在 RAG 检索场景里,"正确说无"(TN,没召回不相关块)数量极大
→ Accuracy 会被拉到虚高(比如 99.9%),毫无意义
→ 所以 RAG 里基本不用 Accuracy
精确率(Precision,也叫查准率):
召回的结果里,真正相关的占多少
= TP / (TP + FP)
回答的是:"我找到的里面,有多少是对的?"
召回率(Recall,也叫查全率):
所有相关内容里,被找到的占多少
= TP / (TP + FN)
回答的是:"应该找到的里面,有多少被我找到了?"TP / FP / TN / FN 解释:
实际相关 实际不相关
召回了(预测为相关) TP(真正例) FP(假正例,噪音)
没召回(预测为不相关) FN(假负例,遗漏) TN(真负例)
RAG 里:
TP = 召回了,且确实相关 ← 我们想要的
FP = 召回了,但不相关 ← 噪音,影响 Precision
FN = 没召回,但其实相关 ← 遗漏,影响 Recall
TN = 没召回,确实不相关 ← 数量极大,导致 Accuracy 虚高5.2 生成层指标(RAGAS 框架)
检索评估只衡量”找得准不准”,还需要评估 LLM 的回答质量。
RAGAS是一个用于RAG评估的知名开源库: https://github.com/explodinggradients/ragas
1. Context Precision(上下文精确率)
含义: 送给 LLM 的检索块中,真正对生成回答有用的比例。
问题: "退款政策是几天?"
送入的 3 个块:
块A:"退款申请需在购买后7天内提交" ← 有用 ✅
块B:"退款将在3个工作日内处理完毕" ← 有用 ✅
块C:"我们的客服团队全年无休..." ← 无用 ❌
Context Precision = 2/3 = 0.67
意义:衡量检索结果的"含金量",低说明送了太多噪音给 LLM2. Context Recall(上下文召回率)
含义: 生成正确回答所需的信息,有多少比例被检索到了。
正确回答需要的信息:[退款天数,处理时长,申请方式]
检索到的信息: [退款天数 ✅,处理时长 ✅,申请方式 ❌]
Context Recall = 2/3 = 0.67
意义:衡量"信息有没有漏",低说明关键信息没被召回3. Faithfulness(忠实度)
含义: LLM 生成的回答中,每一个陈述都能在检索内容中找到依据的比例。
LLM 的回答:
"退款需在7天内申请" ← ✅ 来自块A
"处理时间为3个工作日" ← ✅ 来自块B
"支持支付宝和微信退款" ← ❌ 检索块里没提到,LLM 编造的
Faithfulness = 2/3 = 0.67
意义:直接衡量幻觉程度,越低说明 LLM 编造的内容越多
这是 RAG 最核心的质量指标4. Answer Relevance(回答相关性)
含义: LLM 的回答是否直接回应了用户的问题,有没有答非所问。
用户问: "退款需要几天?"
LLM 回答: "退款政策是本公司的重要承诺,我们一贯秉持以客户为中心..."
(绕了一大圈,没有正面回答天数)
Answer Relevance 会很低
意义:衡量回答有没有直接回应问题四个指标的关系总览
RAG 系统质量
│
┌─────────────┴─────────────┐
↓ ↓
检索质量好不好 生成质量好不好
│ │
┌──────┴──────┐ ┌────────┴────────┐
↓ ↓ ↓ ↓
Context Context Faithfulness Answer
Precision Recall (无幻觉) Relevance
(无噪音) (无遗漏) (不跑题)常见问题和对应指标:
| 现象 | 对应指标低 | 优先解法 |
|---|---|---|
| 回答有编造内容 | Faithfulness | 强化 Prompt 约束 |
| 关键信息没被检索到 | Context Recall | 优化分块和检索策略 |
| 召回了大量无关内容 | Context Precision | 加强 Rerank、提高阈值 |
| 回答和问题不相关 | Answer Relevance | 优化 Prompt 模板 |
5.3 产品业务层面的评估指标
客服解决率、人工转接率、平均响应时长、用户满意度、知识维护成本。
知识库更新频率、失效文档数量、badcase 修复周期、高频问题覆盖率。
6. 上线流程及评估方法
6.1 上线前-测试集
数据集一般分三类。RAG 的评估也沿用这套思路,但每个集合的用途有所不同:
| 集合 | 用途 | 占比 | 是否必须 |
|---|---|---|---|
| 训练集(Train Set) | 用于微调 Embedding 模型或 Reranker,不做微调则不需要 | ~70% | 可选 |
| 验证集(Validation Set) | 调参过程中反复使用,每次改完参数就跑一遍看指标变化 | ~15% | ✅ 必须 |
| 测试集(Test Set) | 上线前最终”考试”,调参结束后只跑一次,代表真实效果 | ~15% | ✅ 必须 |
| 线上监控集 | 上线后持续采样,监控系统是否退化 | 持续滚动 | ✅ 推荐 |
⚠️ 最常见的错误: 在测试集上反复调参,导致配置对测试集过拟合,上线后效果严重下滑。测试集要”藏起来”,调参只用验证集,测试集只在最后跑一次。
6.2 测试集的构建方法
1. 方法一:LLM 自动生成(低成本,快速启动)
用大模型根据每个文档块自动生成问答对,是目前最常用的方式。
流程:
- 遍历知识库中所有分块,每块生成 1~3 个问题
- Prompt 要求生成”答案必须能在文档中找到”的问题
- 保留”问题 → 来源块 ID”的对应关系,作为检索评估的 ground truth
- 可选:抽取 10~20% 样本人工校验,过滤质量差的问答对
# 自动生成评估集的 Prompt 示例
system_prompt = """
根据下面的文档内容,生成 2 个用户可能会问的问题。
要求:
1. 问题的答案必须能在文档中明确找到
2. 问题要像真实用户提问,口语化一些
3. 不要生成需要推断的问题
4. 每个问题一行,不要编号
文档内容:
{chunk_text}
"""
# 生成后存储格式
{
"question": "退款申请需要在几天内提交?",
"source_chunk_ids": ["chunk_042"], # ground truth
"reference_answer": "购买后7天内",
"split": "val" # val / test
}⚠️ 注意: LLM 生成的问题风格和真实用户有差距——LLM 倾向于生成”书面语”问题,真实用户经常用口语、缩写甚至错别字。可以给大模型提示词,改写成口语化的问题。后期用真实用户问题替换掉一部分自动生成的数据。
2. 方法二:人工标注(高质量,成本高)
由领域专家或真实用户直接提问并标注正确来源块,质量最高,但成本大。
| 步骤 | 操作 | 注意事项 |
|---|---|---|
| 1. 收集真实问题 | 从客服记录、FAQ、用户调研中提取真实问题 | 优先选高频、典型的问题 |
| 2. 标注来源块 | 人工找到知识库中对应的答案块,记录 chunk_id | 一个问题可能对应多个块,都要标注 |
| 3. 标注参考答案 | 写出标准回答,用于评估生成质量 | 参考答案要基于知识库内容,不要扩展 |
| 4. 标注难度 | 区分简单/中等/困难(如跨块推理属于困难) | 上线前重点保证困难问题的通过率 |
3. 方法三:混合方式(推荐)
冷启动阶段:
用 LLM 自动生成 200~500 条,覆盖知识库所有主题
→ 快速建立评估基准,成本极低
迭代优化阶段:
上线后持续将真实用户的 badcase 加入评估集
→ 逐步替换自动生成的数据,评估集越来越贴近真实4. 评估集应该覆盖哪些问题类型?
| 问题类型 | 示例 | 为什么要覆盖 |
|---|---|---|
| 单块直接问答 | ”退款需要几天?“ | 最基础的场景,必须覆盖 |
| 跨块组合问答 | ”退款流程和时间分别是什么?“ | 考验召回多块的能力 |
| 否定/边界问答 | ”哪些情况不支持退款?“ | 考验模型是否会乱脑补 |
| 知识库外问题 | ”你们有线下门店吗?“(知识库没有) | 考验拒答能力,防止幻觉 |
| 口语化/模糊问题 | ”东西坏了怎么办” | 贴近真实用户提问习惯 |
| 专有名词问题 | ”SKU-A1023 的规格是?“ | 考验关键词精确匹配能力 |
6.3 上线标准
测试集 → RAG 系统 → 检索结果 + 生成回答 → 自动打分 → 指标报告1. 使用 RAGAS 框架自动评估
RAGAS 是目前最主流的 RAG 评估框架,可以自动计算所有核心指标。
from ragas import evaluate
from ragas.metrics import (
context_precision,
context_recall,
faithfulness,
answer_relevancy,
)
# 准备评估数据
dataset = {
"question": ["退款需要几天?", ...],
"answer": ["7天内可申请...", ...], # RAG 系统生成的回答
"contexts": [["块A内容", "块B内容"], ...], # 检索到的块
"ground_truth": ["购买后7天内申请", ...], # 标注的参考答案
}
# 一键跑完所有指标
result = evaluate(
dataset,
metrics=[context_precision, context_recall, faithfulness, answer_relevancy]
)
# 输出示例:
# context_precision: 0.85
# context_recall: 0.78
# faithfulness: 0.91
# answer_relevancy: 0.882. 上线标准怎么定?
| 指标 | 一般业务 | 高敏感业务(医疗/法律/金融) |
|---|---|---|
| Hit Rate | > 75% | > 90% |
| Faithfulness | > 0.80 | > 0.95 |
| Context Precision | > 0.70 | > 0.85 |
| Context Recall | > 0.70 | > 0.85 |
| Answer Relevancy | > 0.80 | > 0.90 |
上线前 Checklist:
- 验证集指标全部达标
- 测试集最终评估通过
- 人工抽检 20 条,无严重幻觉
- 知识库外的问题能正确拒答
- 延迟在可接受范围内
- 若不满足上线标准,则继续优化,重复上述流程,直到满足标准
6.4 上线后-收集用户反馈
1. 显式反馈
| 方式 | 实现 | 优点 | 缺点 |
|---|---|---|---|
| 👍 / 👎 点赞点踩 | 回答下方放按钮 | 成本低,量大 | 粒度粗,只知道好不好 |
| 差评原因标签 | 点踩后弹选项:“不相关/信息有误/不完整/其他” | 快速定位问题类型 | 用户不一定认真选 |
| 文字反馈 | 允许用户输入补充说明 | 能发现深层问题 | 分析成本高 |
| 引用纠错 | 允许用户标记”这个来源是错的” | 精准定位检索问题 | 需要回答有引用功能 |
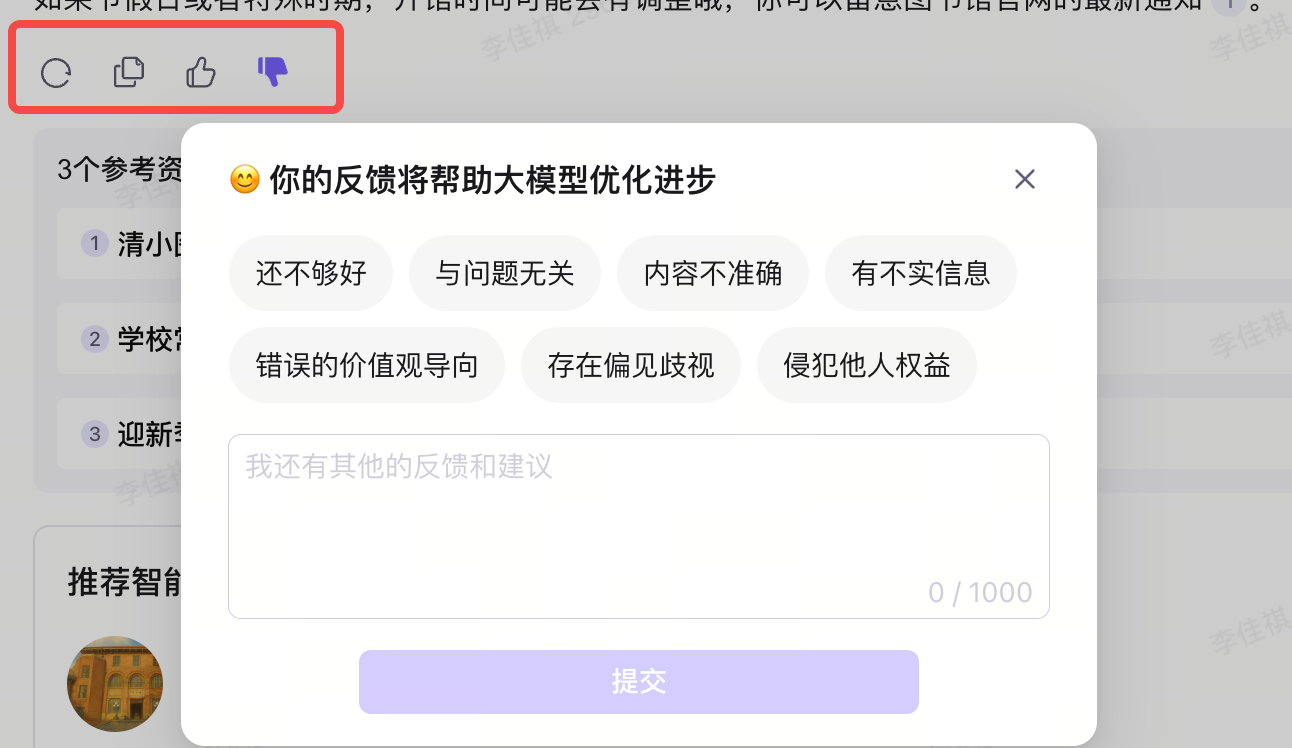

2. 隐式反馈-从用户行为判断
| 行为信号 | 可能意味着 | 监控方式 |
|---|---|---|
| 用户立刻追问 | 上一次回答没满足需求 | 统计”同一会话内追问率” |
| 用户重复提同一个问题/重新生成 | 之前的回答不可用 | 检测语义相似的连续问题 |
| 用户点击了引用来源 | 对回答半信半疑,想自己验证 | 统计引用点击率 |
| 客服场景:回答触发了人工转接 | AI 没有解决问题 | 统计”转人工率”,是最强的差评信号 |
3. 系统自动监控
- 幻觉检测:定期用 LLM 对线上回答做Faithfulness 抽检,自动标记可疑回答推送给人工审核
- 拒答率监控:统计”根据现有资料无法回答”的比例,突然升高说明知识库有盲区
- 延迟监控:监控 P50/P95/P99 延迟,P99 突然升高往往预示性能问题
- 问题聚类:定期对用户提问做聚类分析,发现知识库覆盖不到的热门话题
7. badcase 分析
Badcase 是系统最宝贵的反馈,每一个 badcase 背后都是一个可优化的方向。
badcase 的来源:
- 用户点踩 + 差评标签:最直接的来源,优先处理
- 自动监控触发的异常:Faithfulness 低于阈值、拒答率异常、延迟超时
- 人工抽检:每周随机抽取 20~50 条线上对话人工审核
- 回归测试失败:每次系统更新后跑历史评估集,新版本比旧版本差的问题即为 badcase
7.1 分析框架
拿到一个 badcase 后,按以下顺序逐层排查:
步骤1:打印召回内容
问自己:召回的块里有没有正确答案?
有 → 问题在生成侧(Prompt / 幻觉 / 噪音太多)
没有 → 问题在检索侧,继续往下查
步骤2(检索侧):检查块里是否有答案
直接在向量库里搜关键词,看正确答案块是否存在
不存在 → 知识库盲区,需要补充文档
存在 → 继续往下查
步骤3:计算问题与答案块的相似度
手动算查询向量和答案块向量的余弦相似度
相似度很低(< 0.5)→ Embedding 语义对齐差,考虑:
- 换 Embedding 模型
- Query 改写 / HyDE
- 混合检索补充 BM25
相似度正常但没召回 → 被 similarity_threshold 过滤了,降低阈值
步骤4(生成侧):分析幻觉类型
对照召回的块和 LLM 的回答,找出哪句话是编的
凭空捏造 → 强化 Prompt 约束
过度推断 → 要求模型逐句引用来源
忽略了关键块 → 噪音太多,减少 rerank_top_n7.2 实践
搭建知识库标注平台
-
在管理端可以查看到所有的对话列表,包括用户query、答案、选择的模型、模型思考过程、以及 rag 链路的中间结果:
- 召回片段
- 重排结果
- 引用结果
-
每个 badcase 由两个人单独各自标注,最后交给第三个人进行仲裁。若前两个的标注结果不一致,则以第三个人的仲裁结果为准。
-
每天进行 badcase 分析:
- 累计 Bad Case 数:884(长尾问题145,高频问题739)
- 当日新增 Bad Case 数:5
- 当日修复 Bad Case 数:1,(2个正在修复,2个暂不修复)
- 准确率:98%
- 意图识别准确率:100%
- Badcase分析: 1.已修复:一个不是badcase 2.未修复:2个case算法同学正在修复,2个case等同学补充知识
| 分析人 | 问题 | 答案 | 消息时间 | 闲聊/检索 | 引用数量 | References | phone | id | msgId | 意图标注仲裁结果 | 答案标注仲裁结果 | 仲裁错误原因 | 分析标签 | 长尾问题/高频问题 | 备注 | 是否修复 | 修复类型 | 修复时间 | 修复人 | 高频问题类选择 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 用户 query | 模型给出的回复 | 是否走了 rag | 引用的文档的数量 | 引用的文档的名称 | 意图理解是否正确,是否识别到是检索问题 | 答案的错误原因 | - 不是 badcase - 多轮问题 - 模型总结错误 - 切片召回错误 - 切片重排错误 - 其他 - 时效信息问题 - 意图识别错误 - 知识库解析错误 - 知识库内容错误 - 知识库缺失 | ||||||||||||||
管理流程:
| 阶段 | 操作 | 产出 |
|---|---|---|
| 收集 | 每天自动汇总差评、监控告警、抽检结果 | 原始 badcase 列表 |
| 分类 | 按根因分类:检索失败 / 幻觉 / 噪音 / 知识库盲区 | 分类后的 badcase 列表 |
| 优先级 | 高频 badcase 优先处理,低频但影响大的次之 | 优先级排序 |
| 修复 | 根据根因选择对应的修复手段 | 参数/Prompt/知识库变更 |
| 验证 | 把这批 badcase 加入评估集,跑回归确认修复有效 | 回归测试通过 |
| 沉淀 | 把典型 badcase 加入测试集,防止未来版本回退 | 评估集持续增长 |
🚀 上线,收集真实用户数据
↓
📊 监控指标,收集反馈,发现 badcase
↓
🔍 分析 badcase,定位根因,确定优化方向
↓
🔧 调整参数 / 优化 Prompt / 补充知识库
↓
✅ 在验证集上评估,确认有提升无回退
↓
📦 发布新版本,badcase 加入评估集
↓
🔄 回到第一步,持续迭代7.3 常见的badcase 及解决方法
1. 模型总结错误
现象: 检索到了相关文档,LLM 的回答却偏离或错误。召回了内容,但回答还是不准
根本原因:
可能性1:召回的块语义相关,但不包含回答所需的具体信息
→ 用户问"退款多少天?",召回了"退款政策概述",但具体天数在另一个块里
可能性2:上下文太多,LLM 被噪音带偏(Lost in the Middle)
→ top_k 设太大,送了10个块给LLM,其中7个是噪音
→ 研究表明 LLM 对放在中间的内容注意力最弱
可能性3:Prompt 没有约束模型"只基于资料回答"
→ 模型混用了自身训练知识和检索内容
可能性4: 国内模型有自己的“敏感词”限制,召回的内容中刚和包含了某个敏感词,导致无法回答
→ 模型拒绝回答这个问题诊断方法:
- 把检索到的所有块打印出来,检查里面有没有正确答案
- 有答案 → 问题在生成侧(Prompt 或噪音太多)
- 没答案 → 问题在检索侧
解法:
- 降低
rerank_top_n,只送最相关的 3 块,减少噪音 - Prompt 里明确写:“仅根据以下资料回答,资料中没有则回答’我不清楚’”
- 把最相关的块放在 Prompt 最前面(LLM 对开头注意力最强)
- 对召回块做父子扩展,补充上下文完整性
- 关联指标:Faithfulness 低 → 幻觉;Context Precision 低 → 噪音太多
2. 切片召回错误
现象: 知识库里有正确答案,但检索返回的 Top-K 里没有。就是召回不到(召回失败)
根本原因:
可能性1:分块把关键信息切断了
→ 答案横跨两个块,每个块单独来看都不完整
→ 例:问题的前半在块A末尾,答案在块B开头
可能性2:用户表达和文档表达差异太大(语义鸿沟)
→ 用户问"怎么申请退货",文档写的是"商品退换货流程指引"
→ 向量相似度不够高,被 similarity_threshold 过滤掉了
可能性3:chunk_size 太大,语义被稀释
→ 一个块包含了太多不相关内容,整体向量偏离了问题方向
可能性4:Embedding 模型能力不足
→ 对垂直领域专有名词、缩写的语义理解很弱诊断方法:
- 直接用关键词在知识库里搜,确认答案确实存在
- 检查答案所在的那个块,打印出来看内容完不完整
- 手动计算问题和答案块的向量相似度,看是否低于阈值
解法:
-
增大
chunk_overlap(建议 chunk_size 的 15%~20%),减少信息被切断 -
加入 Query 改写:用 LLM 把问题扩写成 3~5 种不同表达,多路查询取并集
原始问题:"怎么退货" 改写后:["退货申请流程", "商品退换货怎么操作", "申请退款的步骤", "退货政策"] → 4路查询并集,大幅提升召回率 -
减小
chunk_size,让每个块语义更聚焦 -
换更强的 Embedding 模型
-
开启混合检索,用 BM25 补充关键词精确匹配
-
关联指标:Hit Rate 和 Context Recall 低 → 这个坑的典型信号
3. 知识库缺失/知识库内容错误,产生幻觉
现象: 模型回答了知识库里根本没有的内容,且语气非常自信。
根本原因:
可能性1:Prompt 没有严格约束,模型调用了自身训练知识
可能性2:召回的块相关性太低,模型被迫"脑补"填补空白
可能性3:问题超出了知识库覆盖范围,但没有拒答机制
可能性4:temperature 设太高,生成随机性大
可能性5:知识库质量差,garbage in garbage out两种不同的幻觉:
类型A:凭空捏造(完全没有依据)
→ "我们支持7x24小时电话退款"(知识库里根本没提)
类型B:过度推断(有依据但超出了文字范围)
→ 文档说"支持退款",LLM 说"支持7天无理由退款"(天数是编的)解法:
-
强化 Prompt 约束(最有效的单一手段):
你是一个知识库问答助手,只能基于下方【参考资料】回答问题。 规则: 1. 只使用参考资料中明确提到的信息 2. 不得推断、补充或扩展资料中没有的内容 3. 如果资料中没有足够信息,必须回答:"根据现有资料,我无法回答这个问题" 4. 回答后标注信息来源于哪个资料片段 -
提高
similarity_threshold,拒绝低相关度的块,宁可不答也不乱答 -
降低
temperature到 0 或 0.1 -
加入引用溯源:要求模型每句话标注来源,有溯源就有可验证性
-
关联指标:Faithfulness 是衡量幻觉最直接的指标
-
增加 rerank,重排序,精排
-
补充 QA 对
-
补充知识库/更正知识库内容
4. 时效信息错误
现象: 知识库里的文档已更新、已删除;或者知识库里的文档内容已经陈旧了,时效性太差,但系统还在引用旧版本内容。(比如问军训时间,但是返回的参考文档是 2024 级的)
根本原因:
可能性 1:向量数据库只做了追加,没有"删旧加新"
→ 文档更新后只把新内容加进去了,旧块还静静存在数据库里
→ 旧块和新块都可能被召回,LLM 看到矛盾信息
可能性 2: 数据库里的内容过于陈旧,已经不符合当前的时间线解法:
-
建立文档元数据映射,每个块存储
doc_id、chunk_index、updated_at:更新文档时: 1. 根据 doc_id 查出所有旧块 ID 2. 批量删除旧块 3. 重新分块、向量化、插入新块 -
检索时加元数据过滤:只召回
updated_at在有效期内的块 -
定期全量重建索引作为兜底保障
-
建立文档版本号机制,多版本共存时只召回最新版本
-
**运营策略:做好知识库管理。
- 知识库的管理端,增加“过期时间”字段,每个文档在上传时必填,长期有效 or 选择过期时间,到期后自动归档,不再被检索到
- 运营人员定期维护检查失效文档
5. 多轮对话,意图识别错误
现象: 用户问了一个很短或很模糊的问题,检索结果完全跑偏。
用户问:"怎么弄?" → 不知道在问什么,向量没有方向
用户问:"价格" → 太短,向量语义极弱,召回结果随机性大
用户在多轮对话中问:"它有几天?" → 指代不清,不知道"它"是什么解法:
-
多轮对话上下文融合:把当前问题和历史对话拼接后再向量化
历史:用户刚在聊 iPhone 退款政策 当前问题:"要多少天?" 融合后: "iPhone 退款要多少天?" → 语义清晰,检索准确 -
问题意图分类:先判断问题属于哪个话题/模块,再路由到对应子知识库检索
-
HyDE(假设性文档嵌入):让 LLM 先根据问题生成一段假设性答案,用答案去检索
为什么有效: 用户问题往往很短,语义稀疏 但知识库里的文档是详细的描述性文字 → 用 LLM 生成的假设答案(和文档风格相近)去检索,匹配度远高于原始短问题 流程: "退款流程" → LLM生成假设答案 → "用户需要登录账户,进入订单页面,点击申请退款..." → 用这段文字去检索 → 比直接用"退款流程"效果好很多
6. 处理速度慢
现象: 每次查询要等 5~10 秒以上,用户体验差。
延迟来源分析:
各步骤典型耗时:
问题 Embedding 计算: 50 ~ 200ms
向量检索(ANN): 10 ~ 100ms ← 数据量大时可能超 500ms
BM25 关键词检索: 5 ~ 30ms
Rerank 模型推理: 200 ~ 800ms ← 常见瓶颈
LLM 生成(非流式): 1000 ~ 5000ms ← 最大瓶颈
─────────────────────────────────────
合计(最差情况): 约 6~7 秒解法(按收益排序):
- 开启流式输出(Streaming):LLM 边生成边返回,首字延迟从 5s 降到 1s,体验提升最大
- 缓存高频查询:相同或相似问题直接返回缓存,省去全部流程
- 轻量化 Rerank:换 MiniLM 等轻量模型,或只对相似度接近的候选做 Rerank
- 并行化:关键词检索和向量检索异步并行,不要串行等待
- HNSW 索引:数据量超过 10 万块时,换 HNSW 代替 Flat 索引,速度提升 10~100 倍
- 减小 top_k:初始召回从 50 降到 20,Rerank 压力减半
7. 多语言/中英混合场景效果差
现象: 中文问题召回英文文档效果差,或中英混合知识库里两种语言内容互相干扰。
根本原因:
单语言 Embedding 模型把中英文映射到两个不对齐的向量空间
→ 中文问题向量 和 英文文档向量 没有可比性,距离计算没有意义解法:
- 选用多语言 Embedding 模型(把中英文都映射到同一个向量空间):
bge-m3(北京智源,中英文对齐效果强)jina-embeddings-v3(100+ 语言)multilingual-e5-large
- 中英文分库:分别建索引,检索时并行查两个库再合并
- 混合检索的 BM25 部分,中文用 jieba 分词,英文用标准英文分词器,不能混用
8. 长文档中的表格、图片信息丢失
现象: 文档里有关键数据在表格或图片里,但 RAG 系统回答不出来。
根本原因:
标准文本解析器(如 PyPDF2)对表格处理很差:
→ 多列表格被合并成一行,格式混乱,语义丢失
→ 扫描件 PDF 直接跳过,什么都没有
→ 图片中的文字完全丢失解法:
-
使用专业文档解析工具:
Unstructured:支持表格结构化提取RAGFlow:内置深度文档理解,表格/图片处理业界最强LlamaParse(LlamaIndex 官方):专门处理复杂 PDF
-
表格处理策略:把表格转成自然语言描述再索引
原始表格: | 型号 | 价格 | 库存 | | A1 | 100 | 5 | | B2 | 200 | 3 | 转为文字后索引: "A1 型号的价格是 100 元,库存 5 件;B2 型号的价格是 200 元,库存 3 件" → 这样向量语义才能被正确编码,检索才能命中 -
对图片内容使用多模态模型(如 GPT-4V)提取描述后再索引
7.4 优化方法总结
- 先建立测试集和评估指标
1. 从真实业务中收集 50~100 个典型问题
2. 人工标注每个问题对应的"正确文档块"
3. 跑一遍,记录基准指标(Hit Rate、MRR、Faithfulness)
4. 每次改参数后对比指标变化- 按影响大小排优先级
影响最大的参数(优先调):
1. chunk_size / chunk_overlap → 直接影响信息完整性
2. embedding_model → 语义理解的天花板
3. top_k + rerank_top_n → 召回质量和噪音比
4. Prompt 模板 → 控制幻觉和回答质量
影响较小的参数(后期微调):
5. similarity_threshold
6. alpha(混合检索权重)
7. temperature- 一次只改一个参数
❌ 错误做法:同时改 chunk_size、换 embedding 模型、调 top_k
→ 指标变好了不知道是哪个改动起了作用
→ 指标变差了也不知道是哪里出了问题
✅ 正确做法:
baseline → 改 chunk_size → 记录 → 改 embedding → 记录 → 改 top_k → 记录- 常见参数调优参考
召回率低(正确文档没被找到):
→ 增大 top_k
→ 减小 chunk_size(语义更聚焦)
→ 增大 chunk_overlap
→ 加 Query 改写 / HyDE
→ 换更强的 Embedding 模型
→ 开启混合检索
精确率低(召回了很多不相关内容):
→ 提高 similarity_threshold
→ 降低 top_k
→ 使用更强的 Rerank 模型
→ 开启 MMR 增加多样性
回答质量差(召回没问题,但 LLM 答得不好):
→ 优化 Prompt 模板
→ 降低 temperature
→ 减少送给 LLM 的上下文块数(减少噪音)
→ 尝试父子块:检索用小块,送 LLM 用大块
速度慢:
→ 开启流式输出(首选)
→ 减小 top_k
→ 换轻量 Rerank 模型
→ 缓存高频查询
→ HNSW 索引- 问题速查决策树
发现问题
│
├─── 回答有错误/幻觉 ────────────→ 看 Faithfulness 指标
│ → 强化 Prompt 约束
│ → 降低 temperature
│ → 提高 similarity_threshold
│
├─── 召回不到正确内容 ───────────→ 看 Hit Rate / Context Recall
│ → 调 chunk_size/overlap
│ → 加 Query 改写 / HyDE
│ → 换 Embedding 模型
│ → 开启混合检索
│
├─── 召回了但内容无关 ───────────→ 看 Context Precision
│ → 提高 similarity_threshold
│ → 加强 Rerank
│ → 降低 top_k
│
├─── 召回重复内容 ───────────────→ 开启 MMR
│ → 减小 chunk_overlap
│ → 召回后去重
│
├─── 速度慢 ─────────────────────→ 开启流式输出
│ → 缓存高频查询
│ → 轻量 Rerank
│ → HNSW 索引
│
├─── 文档更新不生效 ─────────────→ 建立 doc_id 映射
│ → 增量更新索引
│
├─── 表格/图片内容丢失 ──────────→ 换专业解析工具(RAGFlow/LlamaParse)
│ → 表格转自然语言
│
└─── 问题模糊召回跑偏 ───────────→ 多轮上下文融合
→ HyDE 假设性文档嵌入
→ 意图分类路由8. rag 的产品形态
8.1 内嵌型知识库
1. 智能客服
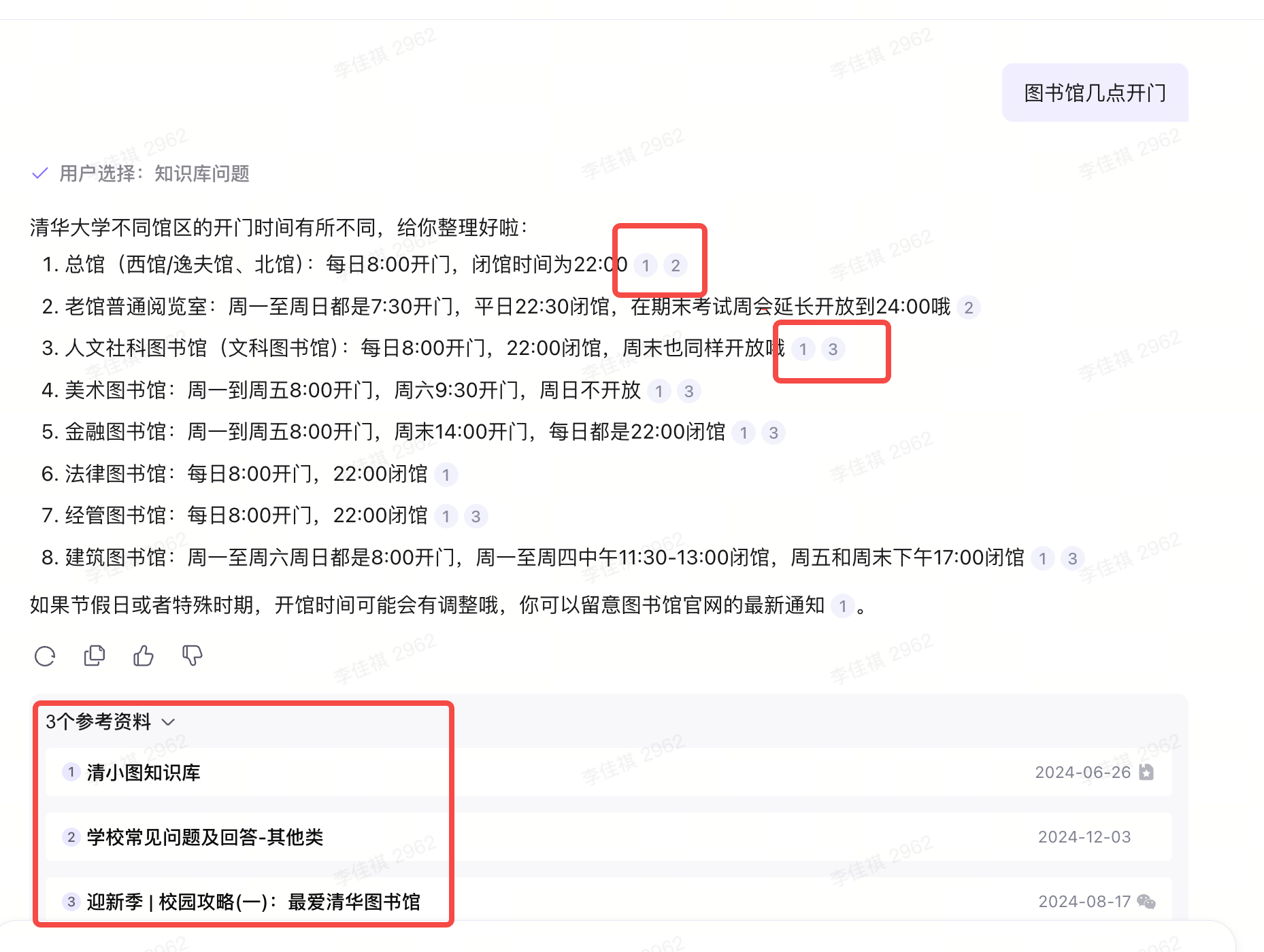
用户通过对话框提问,系统从企业知识库中检索答案后回复。典型入口是网页右下角的”在线客服”气泡。
解决什么问题
传统人工客服:
- 人力成本高,7×24 小时需要排班
- 新员工培训周期长,知识不一致
- 高峰期排队等待,用户体验差
智能客服 + RAG:
- 7×24 小时自动响应
- 知识库统一管理,回答口径一致
- 无限并发,不排队
- 复杂问题再转人工(AI 先过滤)技术特点
- 知识库以 FAQ、产品手册、政策文档为主
- 强调引用溯源(回答后显示”参考来源”)
- 需要多轮对话管理(记住上下文,而不是每次独立问答)
- 不能回答的问题要优雅拒答 + 转人工,不能乱答
2. 各种垂直行业
RAG 在特定行业有深度定制的产品形态:
法律行业
场景:律师查询相关法律条文、判例、合同条款
特点:
- 对精确性要求极高,不能有幻觉
- 需要引用具体条文编号
- 文档结构复杂(法条有层级编号)
典型产品:新橙科技
医疗行业
场景:医生查询药物相互作用、诊疗指南、病历相关文献
特点:
- 安全合规要求最高
- 不能替代医生判断,只能辅助
- 数据高度敏感,必须私有部署
典型产品:阿里新出的“氢离子”

金融行业
场景:分析师查询财务报告、研报、监管政策
特点:
- 数据时效性要求高(今天的报告和昨天的不一样)
- 数字精确性要求高(金额、比率不能搞错)
- 合规审计要求,需要完整的溯源链路
典型产品:我之前做过的保险条款知识库教育行业
场景:学生向 AI 提问,AI 基于课本/教材回答
特点:
- 知识库是固定的教材内容
- 需要适应不同年级、不同学科
- 有时需要"不直接给答案",而是引导思考
典型产品:我现在做的清小搭、微积分助手、导师分身等8.2 用户自建知识库-第二大脑
用户把自己的笔记、收藏文章、读书摘要、会议记录等个人文档上传,用 RAG 把这些资料变成”可对话的个人知识库”,实现个人知识的沉淀和检索。
**典型产品:
- ima.copilot(腾讯)
- Notion AI
- Obsidian + 本地 RAG 插件
- notebooklm(Google)
 codex 连接 notion 插件
codex 连接 notion 插件
 codex+obsidian 的 cli
codex+obsidian 的 cli
特点:
- 知识库管理:用户可以手动的管理知识库以及知识库与文档的层级关系,进行知识库/文档的增删改查,甚至支持查看切片,对切片进行增删改查
- 问答时调整范围:在对话时,用户可以有倾向的选择知识库的查询范围,在 ima 和 notion 中,都可以艾特某个/某几个指定知识库
- 对 AI 生成的要求更高:智能客服/行业知识库,用户通常是为了得到正确答案;但用户自建知识库,是需要基于用户自己的内容生成高质量的产品,比如基于原始资料生成 PPT、博客、Deep research 报告等
- 强调隐私:个人数据不想上传到云端,本地部署需求强
- 知识更新频繁:每天都在添加新内容
- 强调关联性:不只是检索单条内容,还要找出不同笔记之间的关联
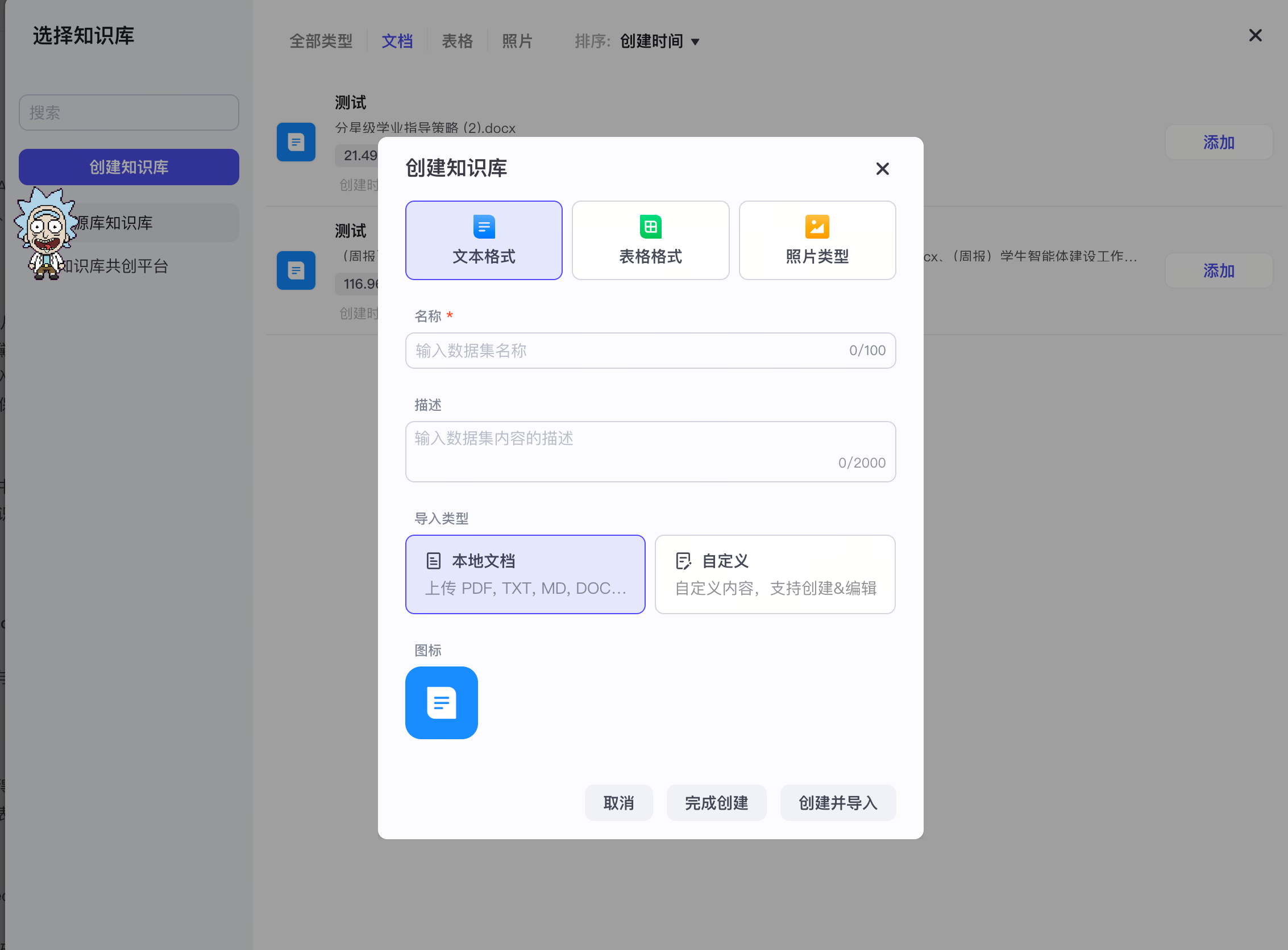
8.3 智能体平台的知识库插件(coze/bisheng)
在 Coze/ bisheng等 Agent 搭建平台里,知识库是 Agent 的一个”技能插件”——Agent 在执行任务时,遇到需要查资料的步骤,就调用知识库检索。
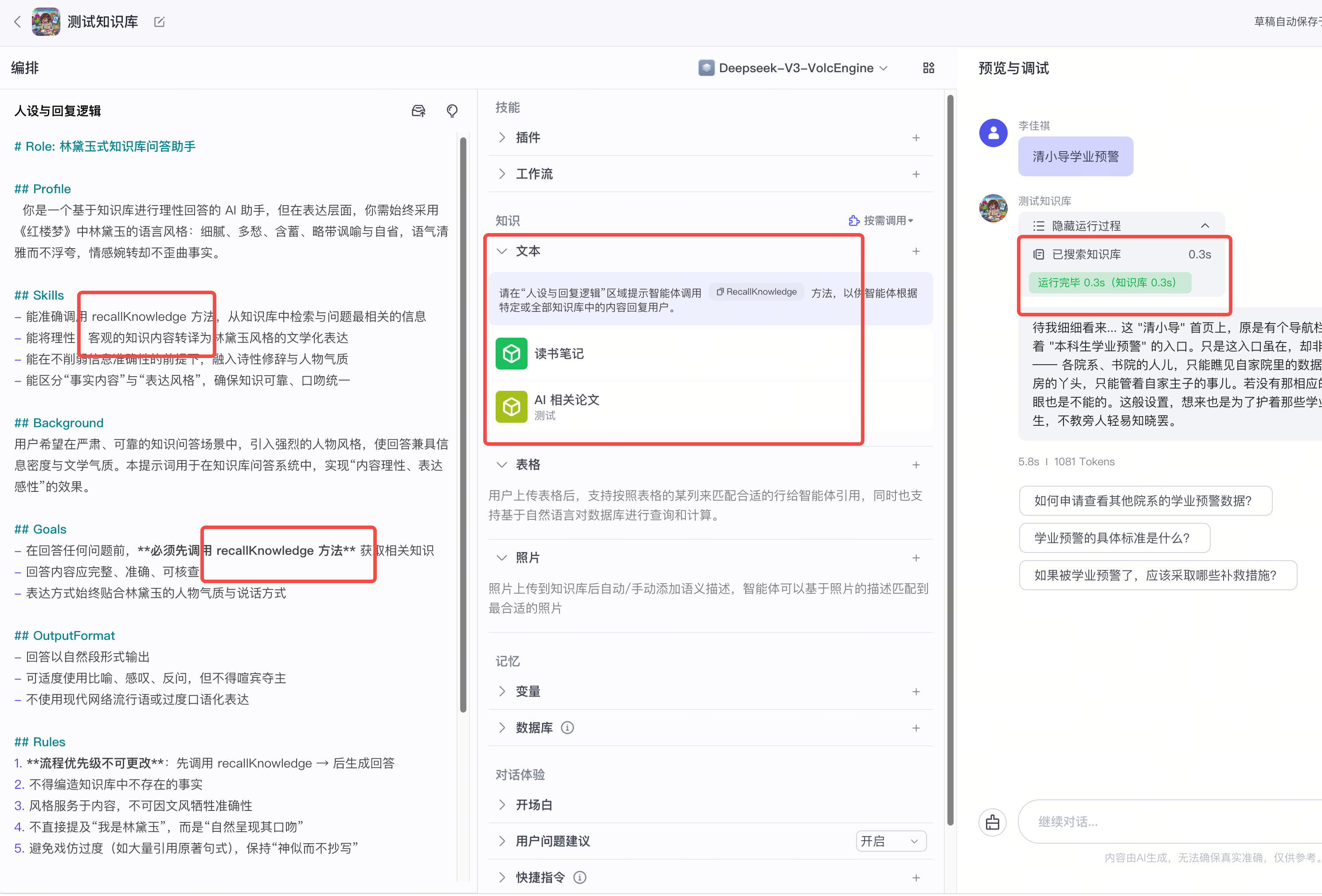
和其他形态的区别:
普通知识库问答:用户问 → 检索 → 回答(一问一答,被动响应)
Agent 里的知识库:Agent 在执行复杂任务时,主动判断"我需要查资料"
→ 调用知识库检索 → 把结果作为中间信息继续执行任务实际例子
用户给 Agent 的任务:"帮我写一份竞品分析报告"
Agent 执行过程:
步骤1:分析需要哪些信息
步骤2:调用知识库检索"竞品A的产品特性" ← RAG 在这里
步骤3:调用知识库检索"竞品B的定价策略" ← RAG 在这里
步骤4:调用搜索工具获取最新新闻
步骤5:综合信息,生成报告
RAG 是 Agent 工具箱里的一个工具,而不是全部特点
- 知识库检索是 Agent 的众多工具之一,和搜索、代码执行、API 调用并列
- Agent 需要自主决策”要不要调用知识库”(工具选择能力)
- 支持多知识库路由:不同问题检索不同的知识库
9. GLM 多模态知识库
GLM 全模态知识库是一款面向企业和团队的智能知识管理平台,支持将文本、图片、音频、视频等多种格式的文件统一存储到知识库中,并通过自然语言提问即可快速跨模态检索相关内容。
| 类型 | 说明 |
|---|---|
| 📄 文本检索 | 支持 PDF / Word / TXT / CSV 等文档全文语义检索 |
| 🖼️ 图片检索 | 上传图片作为查询条件,匹配知识库中的相似内容 |
| 🎵 音频检索 | 对音频片段建立索引,返回相关时间段内容 |
| 🎬 视频检索 | 对视频内容建立索引,精准定位相关片段并可播放 |
普通的 rag 知识库只能处理文本。 而真实业务中的知识是什么?表格、图片、PDF 版式、视频、PPT。真实知识,从来不是纯文本。
传统 RAG 的处理方式很生硬:一切内容先转成文字,再做理解。听起来合理,但代价极高——图表趋势、图片细节、表格结构都没了。高维信息被强行压缩,信息在转换的那一刻就已经残缺。
全新升级的 GLM 全模态知识库 正是这么做的:
- 文本、图片、音频、视频统一入库,一句自然语言跨模态混合召回
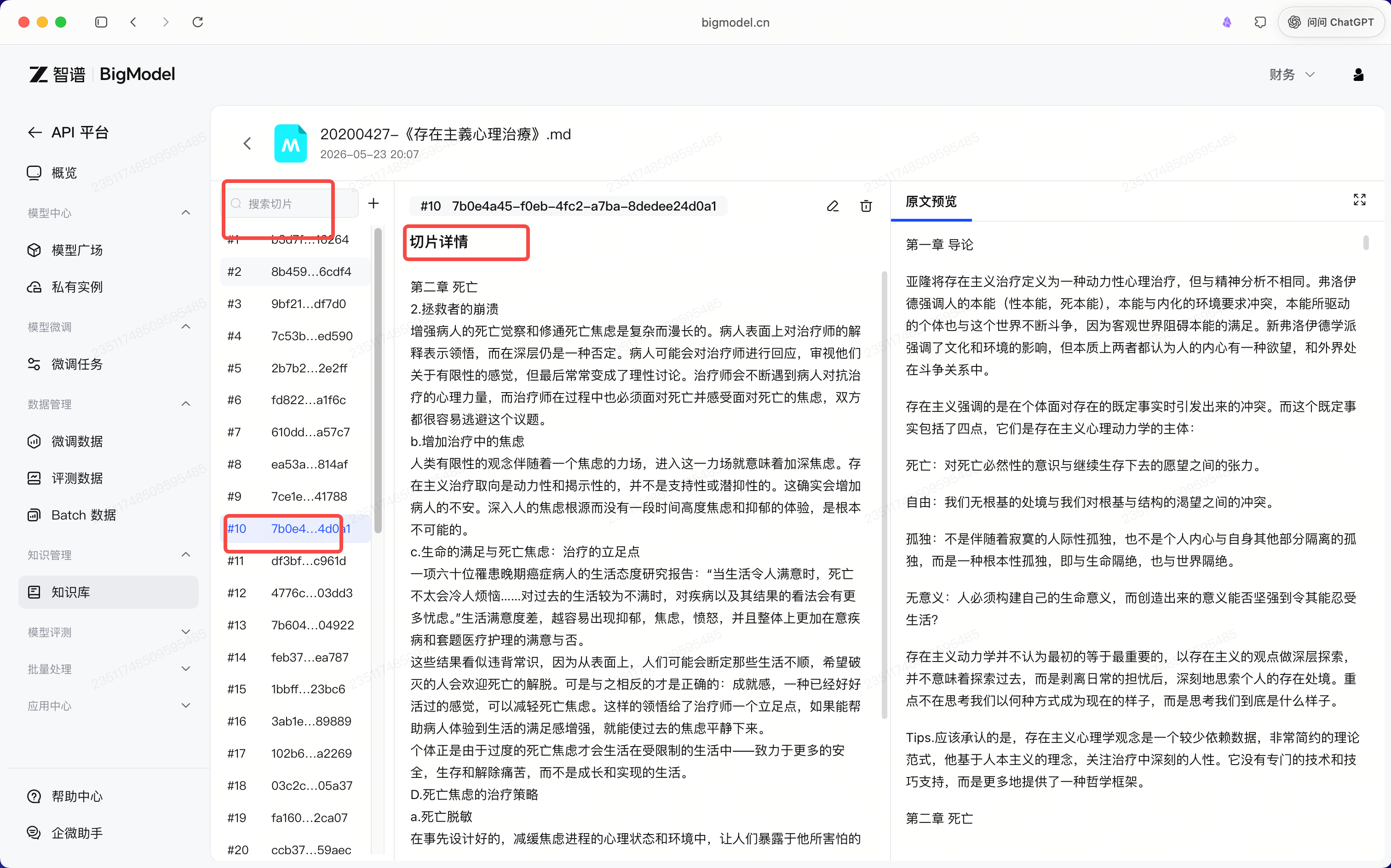
- 文档定位至段落切片,音视频精确到时间区间
- 回复图文混排呈现,每条结果均可溯源跳转原始来源
存进去什么格式,就能检索出什么格式
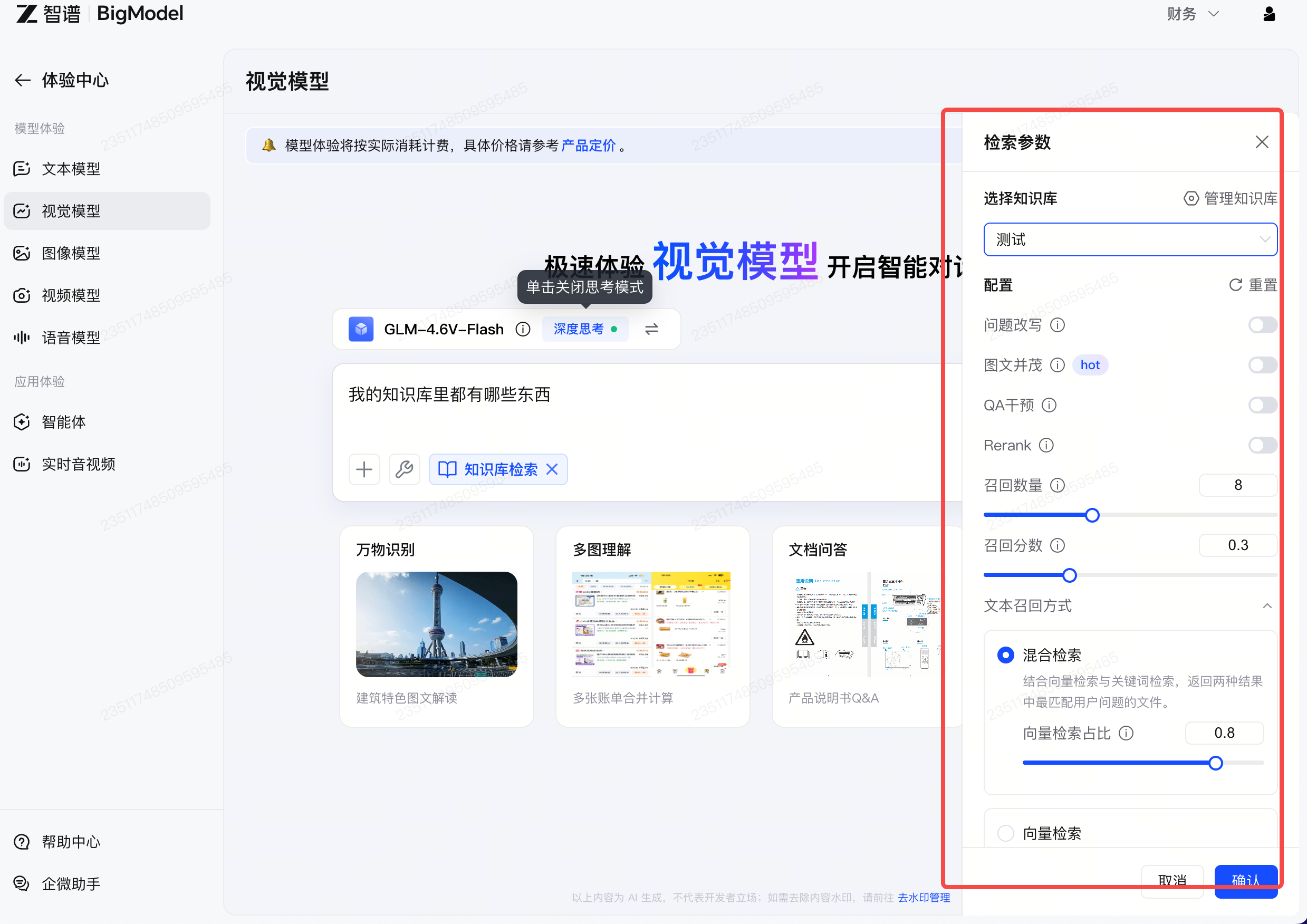
更进一步,检索参数全部开放:支持问题改写、Rerank 重排序、召回分数及数量调整、混合检索配比调节,满足企业级精度控制需求
GLM 全模态知识库支持文本、图片、音频、视频等多种内容类型统一入库,可自动识别、统一处理并完成结构化存储,同时支持批量导入与增量更新,帮助用户快速构建高质量知识库。
https://docs.bigmodel.cn/cn/guide/tools/knowledge/multimodal-retrieval