RAGFlow 在线体验平台
文件列表
切片管理

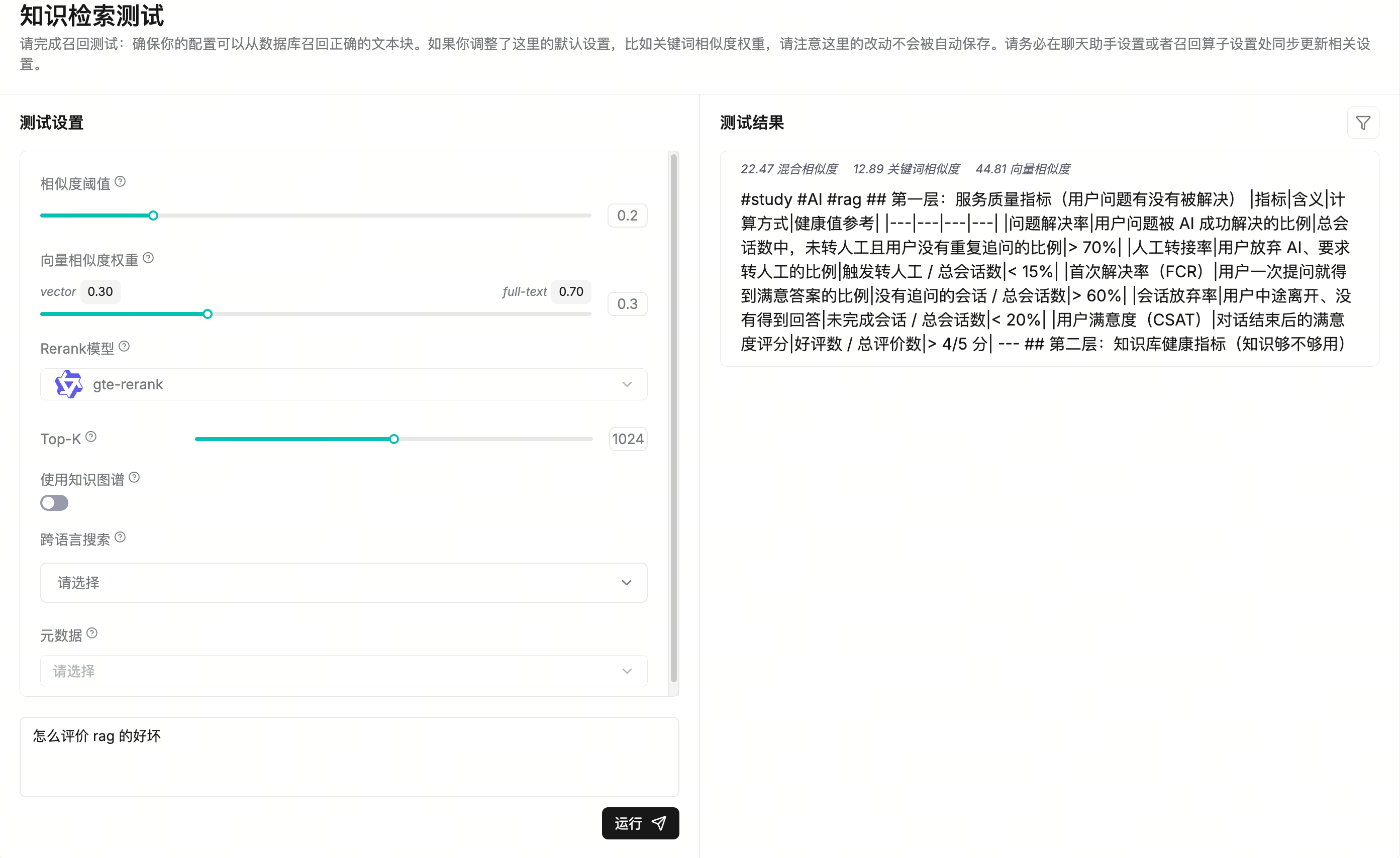
检索检测
配置详细参数
基础信息
| 配置 | 问号说明 / 含义 |
|---|---|
| 名称 | 知识库名称,必填。 |
| 语言 | 文档主语言,影响解析/理解策略。 |
| 头像 | 可上传知识库图片;提示是最多 4MB。 |
| 描述 | 知识库描述。 |
| 权限 | 如果设为“团队”,所有团队成员都可以操作该知识库。 |
| 嵌入模型 | 知识库默认 embedding 模型。已有 chunk 后切换模型会做兼容性校验,新旧向量平均余弦相似度需 >= 0.9,否则要先删除所有 chunk。 |
| 页面排名 PageRank | 检索时给这个知识库额外加权,匹配 chunk 的混合相似度会叠加 PageRank 分数,从而更靠前。 |
| 标签集 | 选择一个或多个标签知识库,给本知识库 chunk 自动打标签;基于文本相似度,可提升检索准确性。标签集是封闭集合,和自动关键词不同。 |
解析 / Ingestion Pipeline
| 配置 | 问号说明 / 含义 |
|---|---|
| 解析方法 | 选择用“内置”还是“选择 pipeline”。 |
| 内置 | 当前使用 RAGFlow 内置切片方法,说明在右侧。 |
| 选择 pipeline | 改用自定义 ingestion pipeline,而不是内置切片方法。 |
General 内置切片配置
| 配置 | 问号说明 / 含义 |
|---|---|
| PDF 解析器 | 用视觉模型分析 PDF 布局,识别标题、文本块、图片、表格位置;选 Naive 只能拿纯文本;只对 PDF 生效。 |
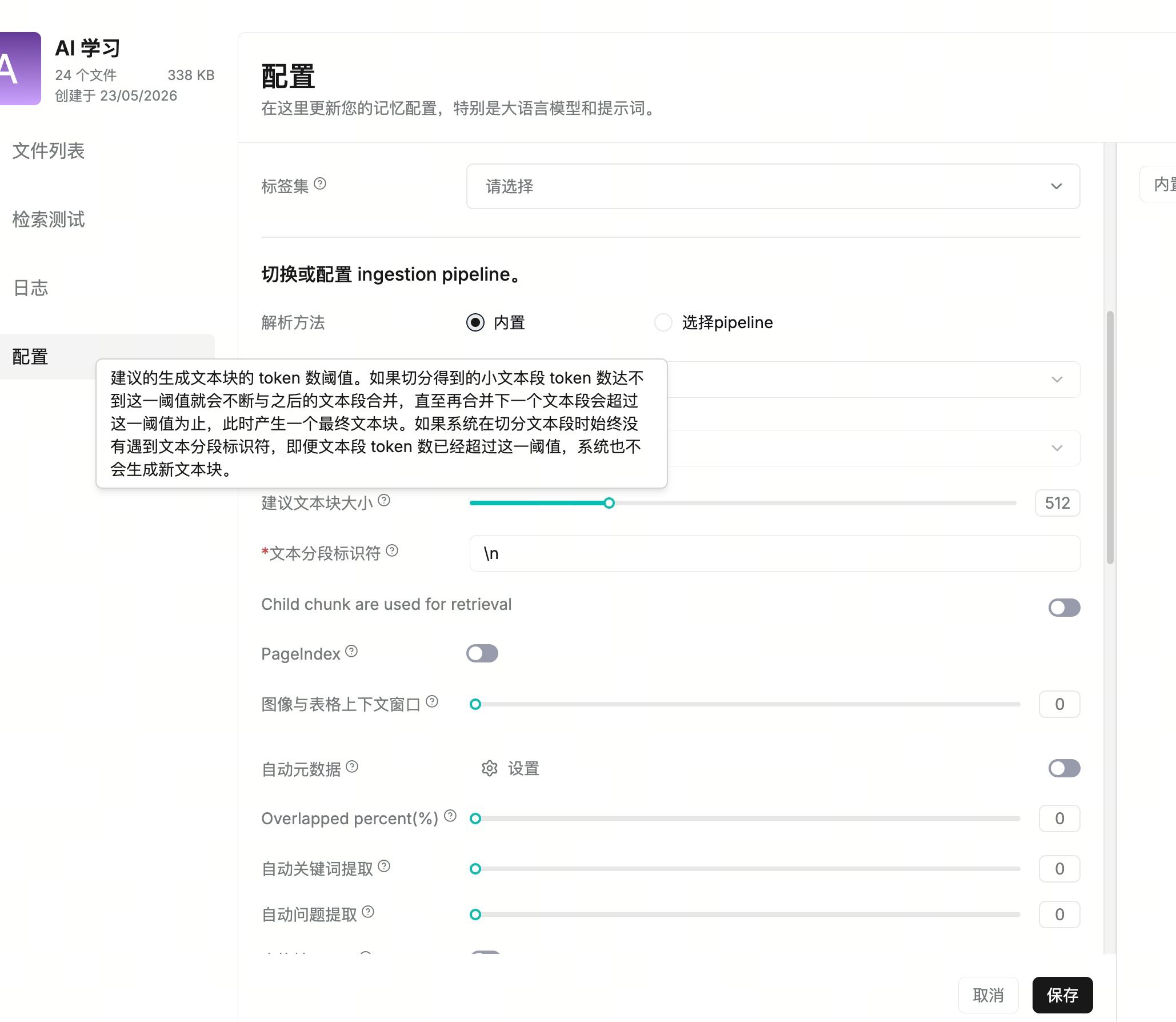
| 建议文本块大小 | chunk token 阈值。小文本段会继续合并,直到再合并会超过阈值才生成 chunk;如果没遇到分段标识符,即使超过阈值也不会强行生成新 chunk。 |
| 文本分段标识符 | 支持多字符分隔符,多字符用反引号包裹;会先按这些标识符切小段,再按建议 chunk 大小拼装。 |
| 子文本块用于检索 | 开启后会生成更细的子 chunk 用于检索,通常适合希望召回更精细片段的场景。 |
| 子文本块分段标识符 | 和上面的分段标识符机制一致,但用于子 chunk。 |
| PageIndex / 目录抽取 | 对已有 chunk 生成每个文件的层级目录;查询时可让大模型判断问题相关目录项,再定位相关 chunk。 |
| 图像与表格上下文窗口 | 抓取图像/表格上下方 N 个 token,给该 chunk 补上下文。 |
| 自动元数据 | 自动生成元数据;只影响新解析文件,已有文件需重新解析;会消耗配置里的索引模型 token。 |
| 重叠百分比 | 相邻两个 chunk 之间保留多少重叠内容。 |
| 自动关键词提取 | 为每个 chunk 提取 N 个关键词,提高查询精度;会消耗索引模型 token,可手动编辑结果。 |
| 自动问题提取 | 为每个 chunk 生成 N 个问题以提升排名得分;失败不会阻断切片,只会留下空结果。 |
| 表格转 HTML | 与 General 搭配。关闭时 Excel 按行解析成键值对;开启时解析为 HTML 表格,超过 12 行会每 12 行拆成多个 HTML 表。 |
全局索引
| 配置 | 问号说明 / 含义 |
|---|---|
| Indexing model / 索引模型 | 用于生成知识图谱、RAPTOR、自动元数据、自动关键词、自动问题;模型能力会影响生成质量。 |
| 提取知识图谱 | 基于知识库所有 chunk 构建知识图谱,提升多跳/复杂问题回答正确率;很耗 token 和时间。 |
| 实体类型 | 知识图谱抽取时关注的实体类别,比如 organization、person、geo 等。 |
| 方法 | Light:用 LightRAG 提示词;General:用 Microsoft GraphRAG 提示词;NER:用 spaCy NER 和规则关键词抽取,快且省资源。当前 UI 主要开放 Light / General。 |
| 批量 chunk token 大小 | 发给 LLM 做实体/关系抽取时,每批 chunk 的 token 上限;NER 不适用。 |
| 实体归一化 | 合并同义实体,让图谱更简洁准确,例如把“特朗普总统 / Donald Trump / Donald J. Trump”合并。 |
| 社区报告生成 | 将实体关系聚成层级社区,再用 LLM 生成社区摘要报告。 |
RAPTOR
| 配置 | 问号说明 / 含义 |
|---|---|
| 使用召回增强 RAPTOR 策略 | 适合复杂多跳问答;需要在文件页通过“生成 > RAPTOR”开启。 |
| 生成范围 | 选择 RAPTOR 生成范围:整个知识库或单个文件。 |
| 提示词 | 给 LLM 的任务说明和输出要求,可用变量传入内容。 |
| 最大 token 数 | 每个被总结文本块的最大 token 数。 |
| 阈值 | chunk 聚类所需的最小语义相似度;越高每组越少,越低每组越多。 |
| 聚类方法 | GMM 或 AHC;AHC 可支持更大最大聚类数,但大规模输入更占内存。 |
| 最大聚类数 | 最多创建多少个聚类。 |
| 随机种子 | 伪随机算法起点,保证多次运行可复现。 |
搭建 rag 聊天助手
每个参数都可以自定义设置
| 参数 | 当前值/状态 | 问号提示的意思 |
|---|---|---|
| 系统提示词 | 文本框 | 给 LLM 的总指令,比如角色、回答长度、语气、语言、是否只能基于知识库回答等。{knowledge} 是系统保留变量,代表检索召回的知识库文本块。 |
| 相似度阈值 | 0.2 | 检索时会计算“混合相似度”。低于这个阈值的文本块会被过滤掉。默认 0.2,大致表示混合相似度分数至少 20 才会召回。 |
| 向量相似度权重 | vector 0.30 / full-text 0.70 | 混合得分由向量语义相似度和全文/关键词相似度组成,两个权重相加为 1.0。当前更偏全文关键词匹配,语义向量占 30%。如果启用 Rerank,向量相似度部分会被 rerank 分数替代。 |
| Top N | 8 | 不是所有超过相似度阈值的块都会给 LLM,只会把排名最高的 Top N 个文本块放进上下文。 |
| 多轮对话优化 | 关闭 | 多轮对话时,会根据历史上下文优化当前查询问题。好处是更懂上下文,代价是额外调用大模型、消耗 token。 |
| 使用知识图谱 | 关闭 | 是否在检索时使用所选知识库里的知识图谱,适合复杂多跳问题。会检索实体、关系、社区报告等文本块,所以检索时间会明显变长。 |
| 推理 | 关闭 | 是否启用类似 DeepSeek-R1 / OpenAI o1 的推理工作流,让模型分步骤处理复杂问题。适合逻辑、多步问题,但更慢、更耗资源。 |
| Rerank 模型 | 未选择 | 可选。为空时用“关键词相似度 + 向量相似度”;选了 rerank 后,用“关键词相似度 + rerank 分数”。能提升排序质量,但会显著增加响应时间。 |
| 变量 | knowledge | 配合系统提示词使用的变量。knowledge 是保留变量,表示召回的知识库内容;变量需要用 {} 写进系统提示词。 |
| 模型 | deepseek-chat | 用于最终生成回答的大语言模型。 |
| 自由度 | 平衡 | 一个快捷档位,控制模型回答保守还是发散;对应温度、Top P、惩罚项等参数组合。 |
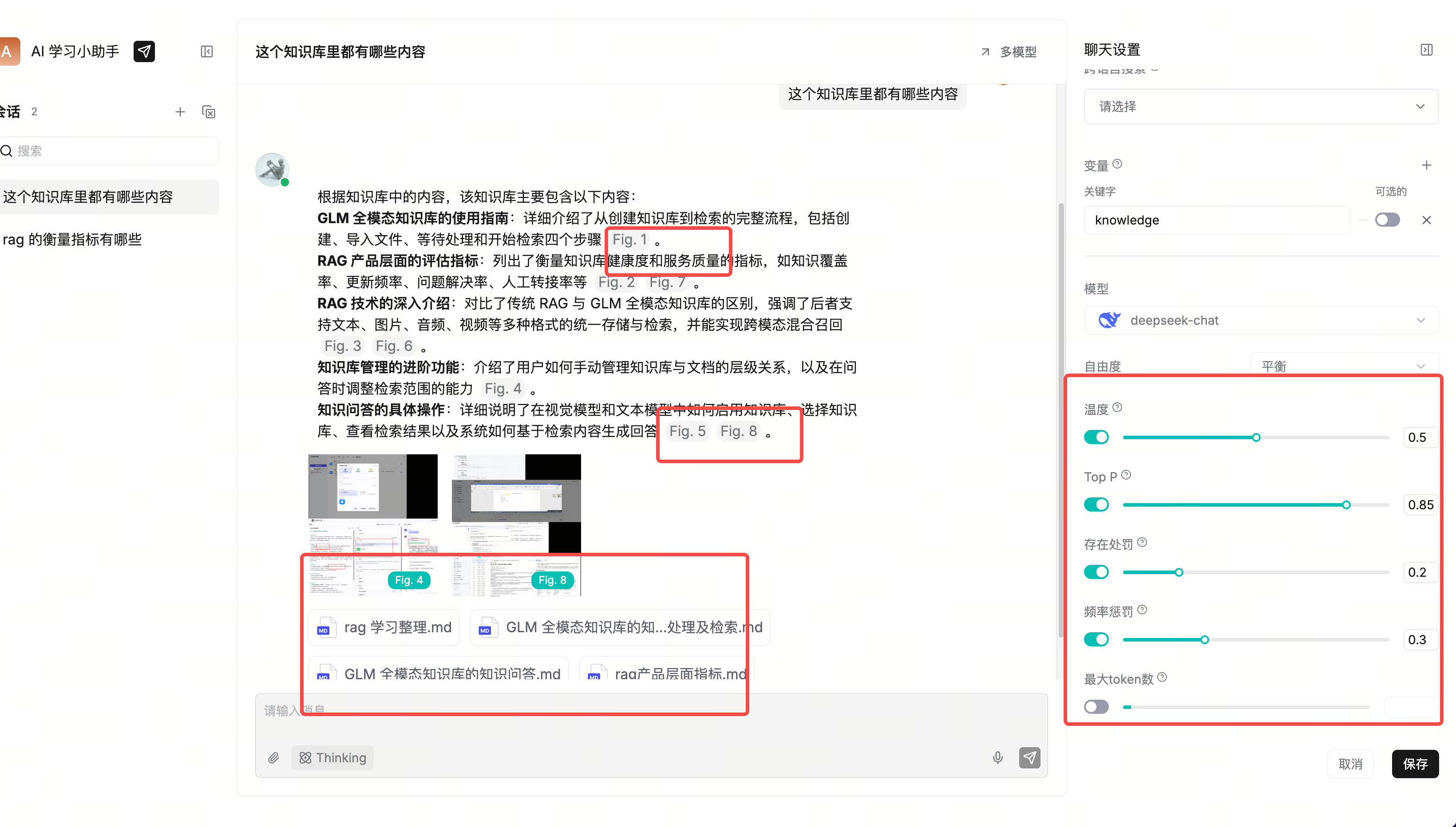
| 温度 | 0.5 | 控制随机性。越低越稳定保守,越高越有创造性和多样性。 |
| Top P | 0.85 | 核采样参数,只在累计概率达到 P 的候选词集合里采样。越低越收敛,越高越开放。 |
| 存在处罚 | 0.2 | 惩罚已经出现过的内容,鼓励模型引入新信息,减少一直围绕同一点重复。 |
| 频率惩罚 | 0.3 | 惩罚频繁重复的词或短语,降低机械重复。 |
| 最大 token 数 | 关闭/未填 | 限制单次回答的最大输出长度;值不合理可能导致报错。 |
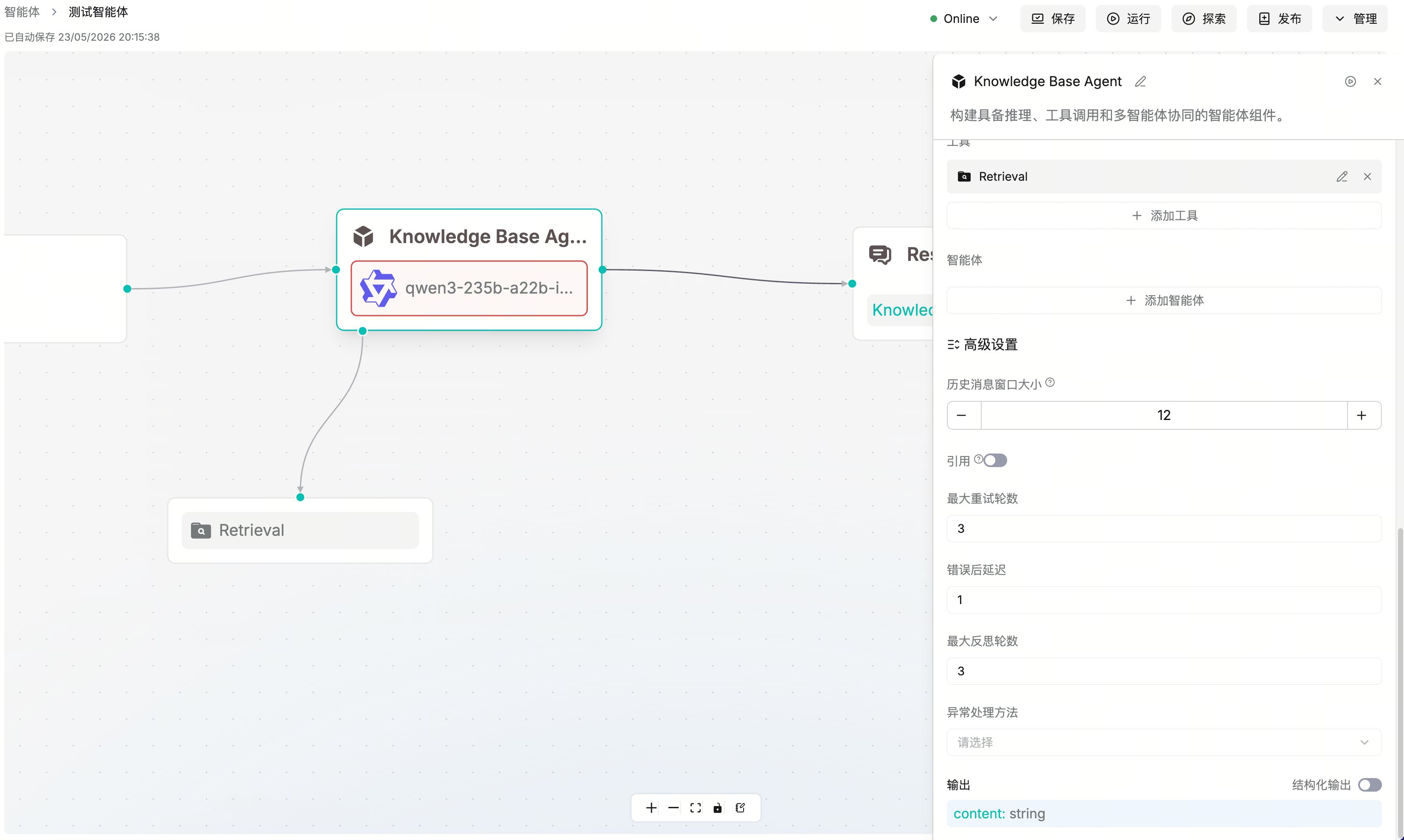
创建智能体